



性能优化之服务压测
一、性能问题分析
性能优化的目标
当我们说要对一个系统做性能优化的时候,我们的目标是什么,需要优化到一个什么样的水平才算合格?
应用性能是产品用户体验的基石,性能优化的终极目标是优化用户体验。当我们谈及性能,最直观能想到的一个词是“快”,哪到底怎么才是快呢?如何又为慢!
3S定理
Strangeloop在对众多的网站做性能分析之后得出了一个著名的3s定律“页面加载速度超过 3s,57%的访客会离开”。
接口速度在Google、百度等搜索引擎的PR评分中也占有一定的比例,会影响到网站的SEO排名。
不同端关注的指标
后端:RT、TPS、并发数、Throughput、Footprint、Latency
Web端:首屏时间、白屏时间、可交互时间、完全加载时间...
移动端:端到端响应时间、Crash率、内存使用率、FPS...
影响性能的关键要素
产品设计:产品逻辑、功能交互、动态效果、页面元素
基础网络:网络 = 连接介质 + 计算终端
连接介质:电缆、双绞线、光纤、微波、载波或通信卫星。
计算终端:PC、手机、可穿戴设备、家具家电... 基础网络设施,互联网,局域网(LAN)、城域网(MAN)、广域网(WAN)
代码质量&架构
移动端环境
硬件及云服务
二、压力测试
什么是压力测试?
压力测试(英语:Stress testing)是针对特定系统或是组件,为要确认其稳定性而特意进行的严格测 试。会让系统在超过正常使用条件下运作,然后再确认其结果。
压力测试是对系统不断施加压力,来预估系统服务能力的一种测试。
为什么对系统压测呢?有没有必要。压不压测要看场景!
一般而言,只有在系统基础功能测试验证完成、系统趋于稳定的情况下,才会进行压测。
压测的目的是什么?
当负载逐渐增加时,观察系统各项性能指标的变化情况是否有异常
发现系统的性能短板,进行针对性的性能优化
判断系统在高并发情况下是否会报错,进程是否会挂掉
测试在系统某个方面达到瓶颈时,粗略估计系统性能上限
....
压测性能指标有哪些?

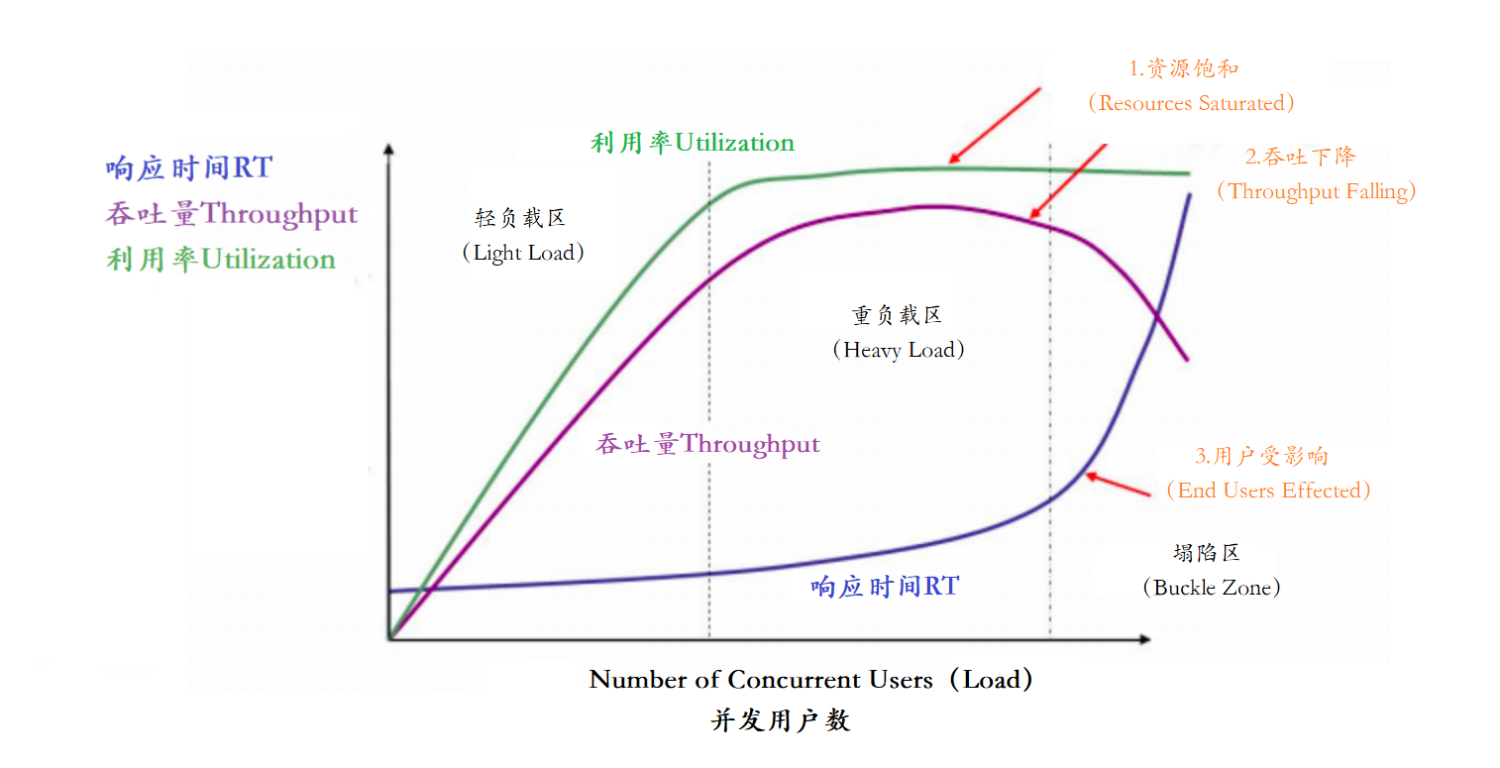
以上主要的四种性能指标【响应时间、并发用户数、吞吐量、资源使用率】它们之间存在一定的相关性,共同反映出性能的不同方面。
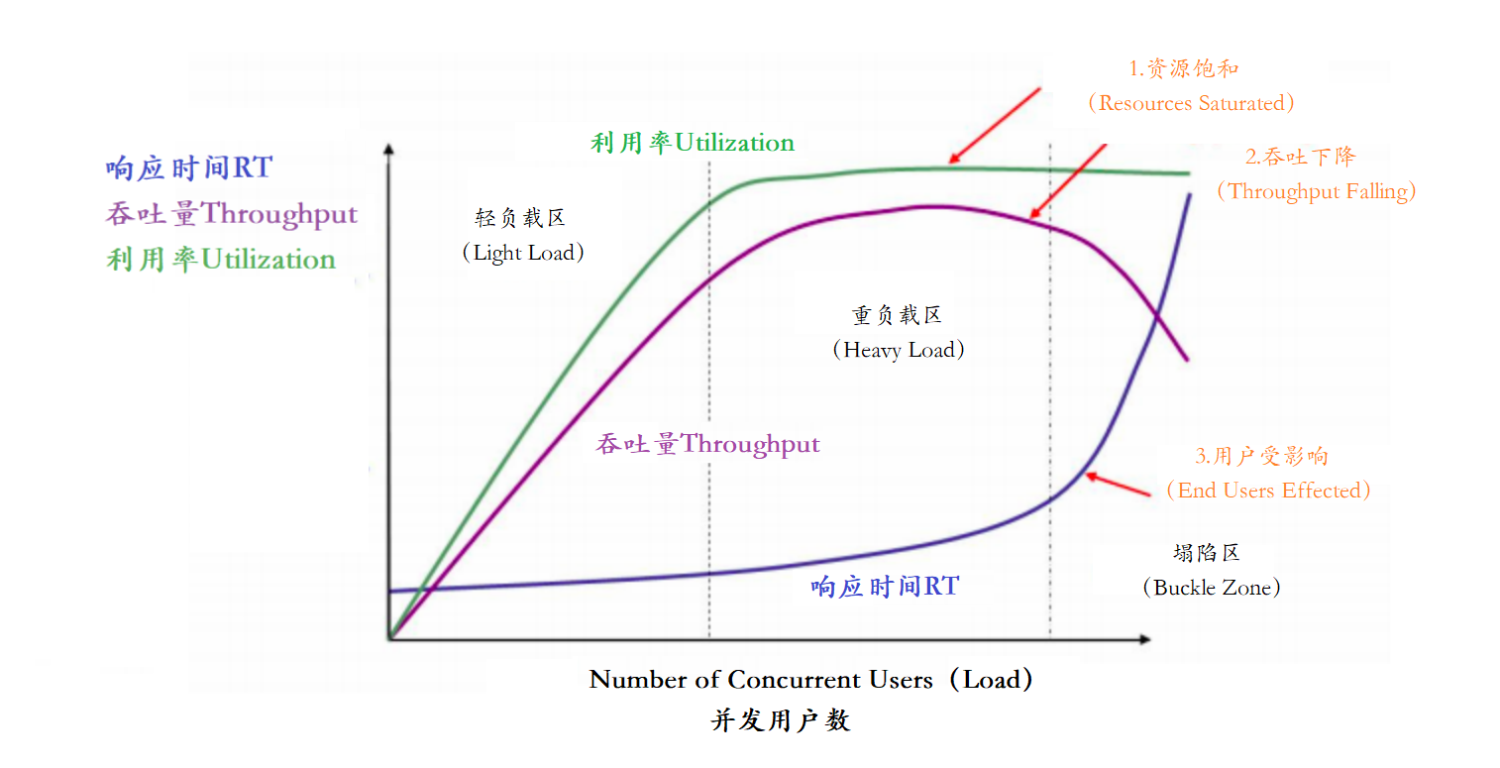
在这个图中,定义了三条曲线、三个区域、两个点以及三个状态描述。
三条曲线:
吞吐量的曲线(紫色)
利用率(绿色)
响应时间曲线(深蓝色)
三个区域:
轻负载区(Light Load)
重负载区(Heavy Load)
塌陷区(Buckle Zone)
两个点:
最优并发用户数(The Optimum Number of Concurrent Users)
最大并发用户数(The Maximum Number of Concurrent Users)
三个状态描述:
资源饱和(Resource Saturated)
吞吐下降(Throughput Falling)
用户受影响(End Users Effected)
常用压测工具
Apache JMeter : 可视化的测试工具
Apache的ab压力测试
Nginter 韩国研发
PAS 阿里测试工具
MeterSphere :国内持续测试的开源平台
等等
Apache JMeter是Apache组织开发的基于Java的压力测试工具。用于对软件做压力测试,它最初被设计 用于Web应用测试,但后来扩展到其他测试领域。 它可以用于测试静态和动态资源,例如静态文件、 Java 小服务程序、CGI 脚本、Java 对象、数据库、FTP 服务器, 等等。
官网地址:https://jmeter.apache.org/
中文社区:http://www.jmeter.com.cn/2747.html
JMeter压测环境架构图:
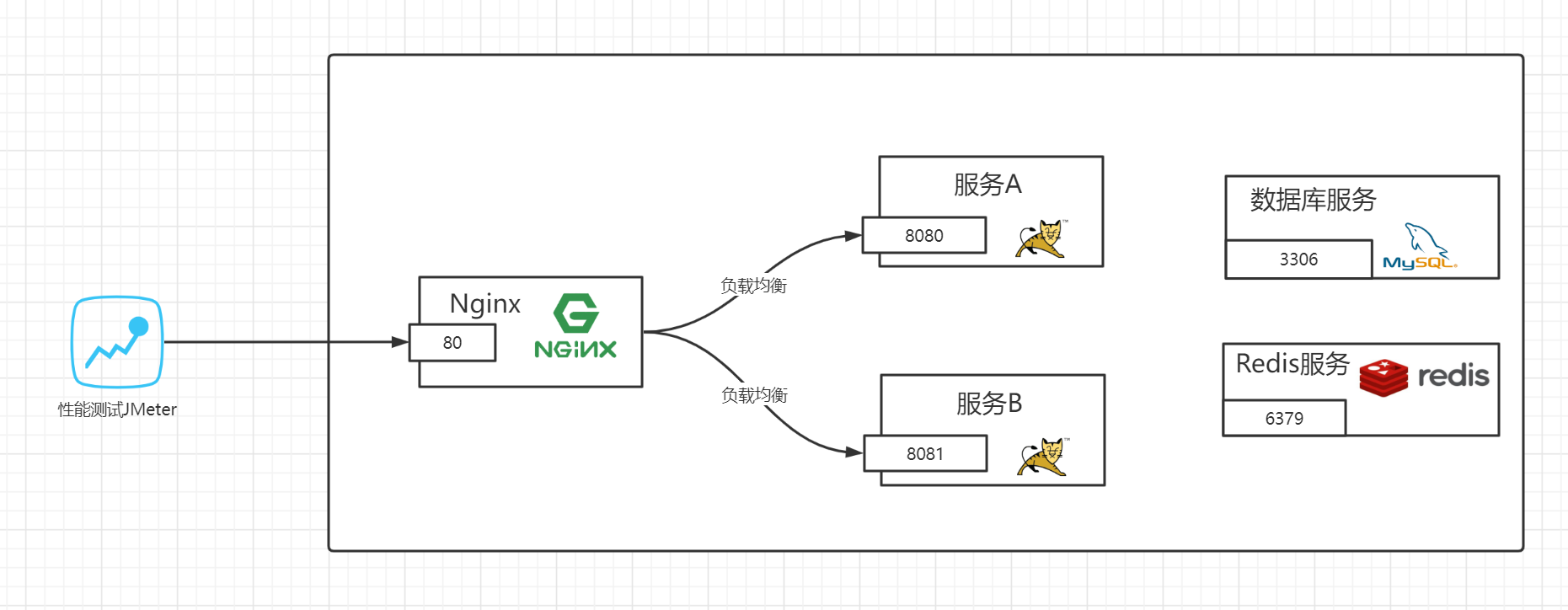
压测目标总的来说有4条:
负载上升各项指标是否正常
发现性能短板
高并发下系统是否稳定
预估系统最大负载能力
三、压测性能关键指标分析
系统负载(load average)
什么是Load Average?
系统负载System Load是系统CPU繁忙程度的度量,即有多少进程在等待被CPU调度(进程等待队 列的长度)。
平均负载(Load Average)是一段时间内系统的平均负载,这个一段时间一般取1分钟、5分钟、 15分钟
多核CPU和单核CPU的系统负载数据指标的理解还不一样。
举个栗子:while(true) 这样程序不耗时,cpu会飙高,但是load average不会走高。说明程序在计算,但是并没有执行耗时工作,所以Load Average并不高。我们在核查服务器负载因需要重点关注load average。
服务器上执行以下命令可以查看服务器的负载情况:
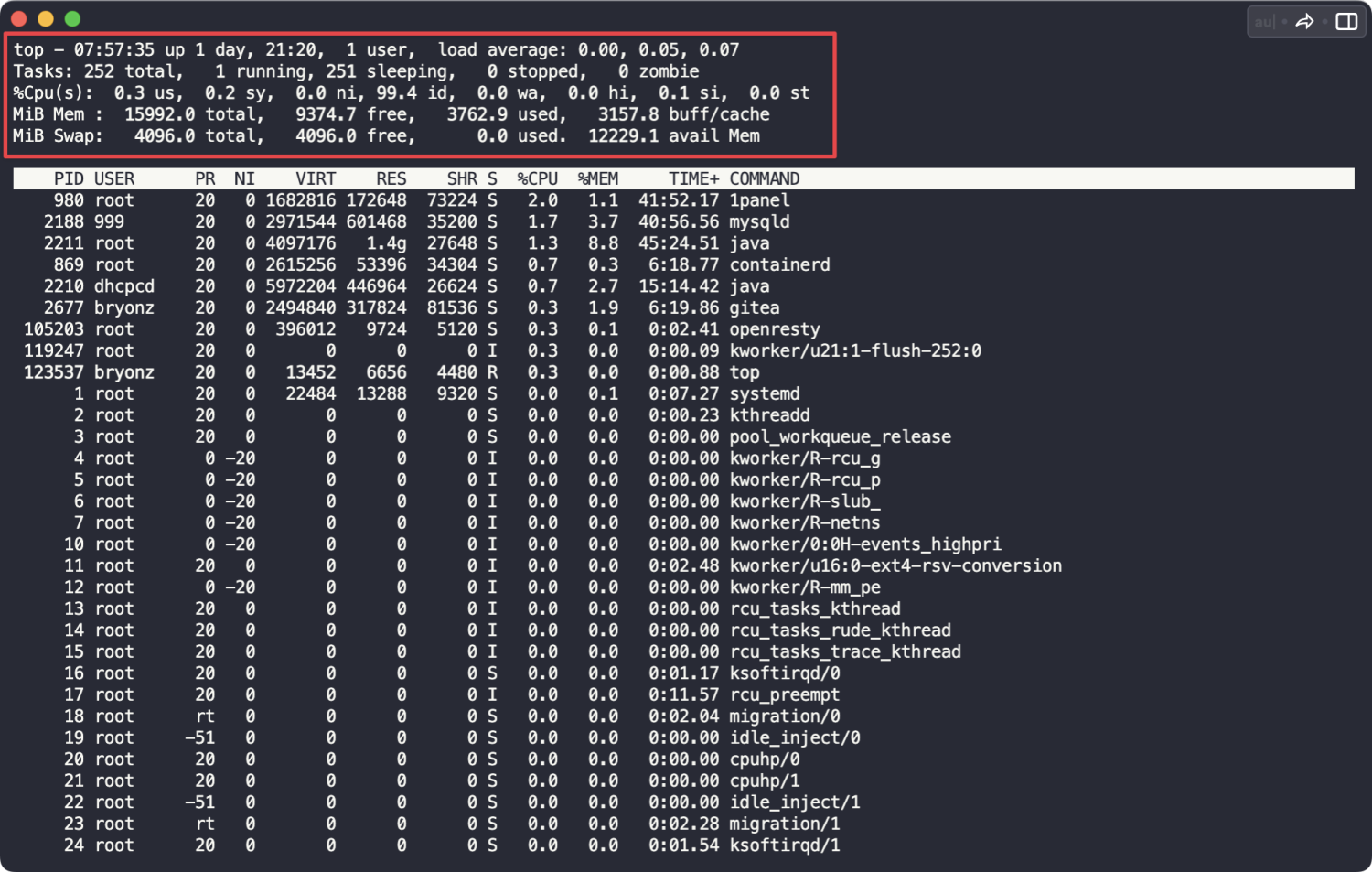
top
top -H如下图所示,可以看到系统负载 load average 载分别是 0.12, 0.11, 0.08;

统计信息区前五行是系统整体的统计信息:
Load的数值是什么含义?
不同的CPU性质不同:单核,双核,四核 -->>
单核CPU三种Load情况
举例说明:把CPU比喻成一条(单核)马路,进程任务比喻成马路上跑着的汽车,Load则表示马路的繁忙程度。
情况1-Load小于1:不堵车,汽车在马路上跑得游刃有余:

情况2-Load等于1:马路已无额外的资源跑更多的汽车了:

情况3-Load大于1:汽车都堵着等待进入马路:

双核CPU
如果有两个CPU,则表示有两条马路,此时即使Load大于1也不代表有汽车在等待:
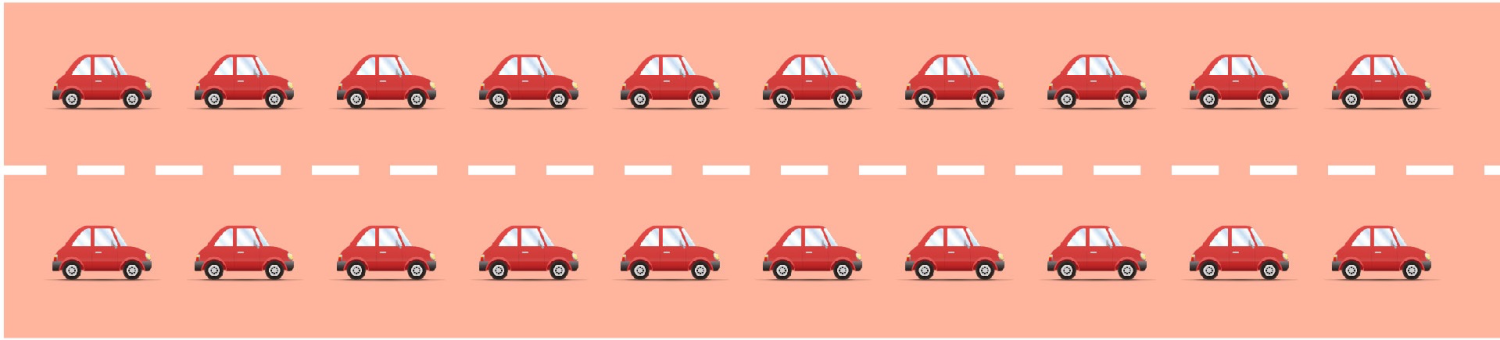
[Load==2,双核,没有等待]
什么样的Load值得警惕?
如下分析针对单核CPU
【0.0 - 0.7]】 :系统很闲,马路上没什么车,要考虑多部署一些服务
【0.7 - 1.0 】:系统状态不错,马路可以轻松应对
【等于1.0】 :系统马上要处理不多来了,赶紧找一下原因
【大于5.0】 :马路已经非常繁忙了,进入马路的每辆汽车都要无法很快的运行
不同Load值说明什么问题?
如下分析针对单核CPU的四种情况:
情况1:1分钟负载 > 5,5分钟负载 < 1,15分钟负载 < 1
举例: 5.18 , 0.05 , 0.03
短期内繁忙,中长期空闲,初步判断是一个“抖动”或者是“拥塞前兆”
情况2:1分钟负载 > 5,5分钟负载 > 1,15分钟负载 < 1
举例: 5.18 , 1.05 , 0.03
短期内繁忙,中期内紧张,很可能是一个“拥塞的开始”
情况3:1分钟负载 > 5,5分钟负载 > 5,15分钟负载 > 5
举例: 5.18 , 5.05 , 5.03
短中长期都繁忙,系统“正在拥塞”
情况4:1分钟负载 < 1,5分钟负载 > 1,15分钟负载 > 5
举例: 0.18 , 1.05 , 5.03
短期内空闲,中长期繁忙,不用紧张,系统“拥塞正在好转”
内存
系统在处理请求过程中占用的内存资源,主要影响 GC 行为和系统稳定性。
关注点:
持续增长:若内存使用在压测过程中不断上升,可能存在内存泄漏,或者缓存未命中造成堆积。
频繁 GC:说明内存吃紧,频繁 Minor GC 会拖慢响应,Full GC 更严重,直接造成系统卡顿或暂停。
压测建议:
压测过程中内存占用应趋于平稳。
Full GC 次数控制在极少发生(或为0)。
网络IO
数据在服务与客户端、或服务之间传输所消耗的网络资源。
关注点:
带宽使用率:压测期间带宽占用超过 70% 往往意味着接近瓶颈。
连接建立与关闭频率:高频连接/断开容易导致 TIME_WAIT 积压,建议连接复用(如 HTTP Keep-Alive)。
小包高频 vs 大包低频:小包高频更容易触发系统调用和中断,更吃网络资源。
磁盘IO
系统对硬盘的读取与写入能力,尤其影响到日志、大数据文件、数据库等场景。
关键指标:
IOPS(每秒IO操作次数):衡量磁盘并发处理能力。
机械硬盘:100 ~ 200 IOPS(高于 500 就算高压)
消费级SSD:2000 ~ 50000 IOPS
企业级NVMe SSD:高达百万 IOPS(如 500K - 1M+)
延迟:
机械硬盘:> 5ms 较高
SSD:< 1ms 为佳,> 5ms 说明负载偏高
RT(响应时间)
一次请求从发送到收到响应的全程时间,包括排队、处理、网络等。
说明:
平均值不可单独参考:需重点关注 P90、P95、P99,尤其是 P99,用于衡量尾部性能。
请求RT的组成:排队等待时间 + 后端处理时间 + 网络传输时间
压测目标参考:
核心业务接口 P99 ≤ 200ms 属于良好。
若 P99 超过 1s,应检查是否存在热点、资源竞争或阻塞。
TPS(Transactions Per Seconds,吞吐量)
系统单位时间内成功处理的请求数量,是衡量系统整体处理能力的核心指标。
说明:
TPS 增长 vs RT 增长:正常情况下,TPS 增加,RT 稍增长;若 TPS 稳定但 RT 飙升,说明系统达到瓶颈。
瓶颈判断方法:TPS 提升至某值后无法再增长,RT、Active Thread 持续上升,说明系统“顶住了”。
水平扩展能力:服务实例翻倍,TPS 是否接近线性增长(如从 500 提升到 1000)是可扩展性的体现。
Active Thread(活跃线程数)
当前正在处理请求的线程数量,是衡量并发处理压力的重要指标。
说明:
线程池设计是否合理:活跃线程接近最大线程数时,说明线程池已满,可能出现排队或拒绝请求。
线程数上升但 TPS 无增长:
多见于下游依赖慢或阻塞,如数据库慢查询、外部接口响应慢、文件IO写满等。
此时线程被“挂起”,造成线程堆积。
线程长期不释放:可能存在业务阻塞、死锁或代码未及时关闭连接等问题。
💡 可不可以基于RT与TPS算出服务端并发线程数?
答:可以,服务端线程数计算公式:TPS/ (1000ms/ RT均值)
RT=21ms,TPS=800,服务端线程数:= 800/ (1000ms/ RT均值) = 17
RT=500ms,TPS=800,服务端线程数:= 800/ (1000ms/ RT均值) = 400
RT=1000ms,TPS=800,服务端线程数:= 800/ (1000ms/ RT均值) = 800
四、搭建压测监控平台
Docker+JMeter+InfluxDB+Grafana+node_exporter
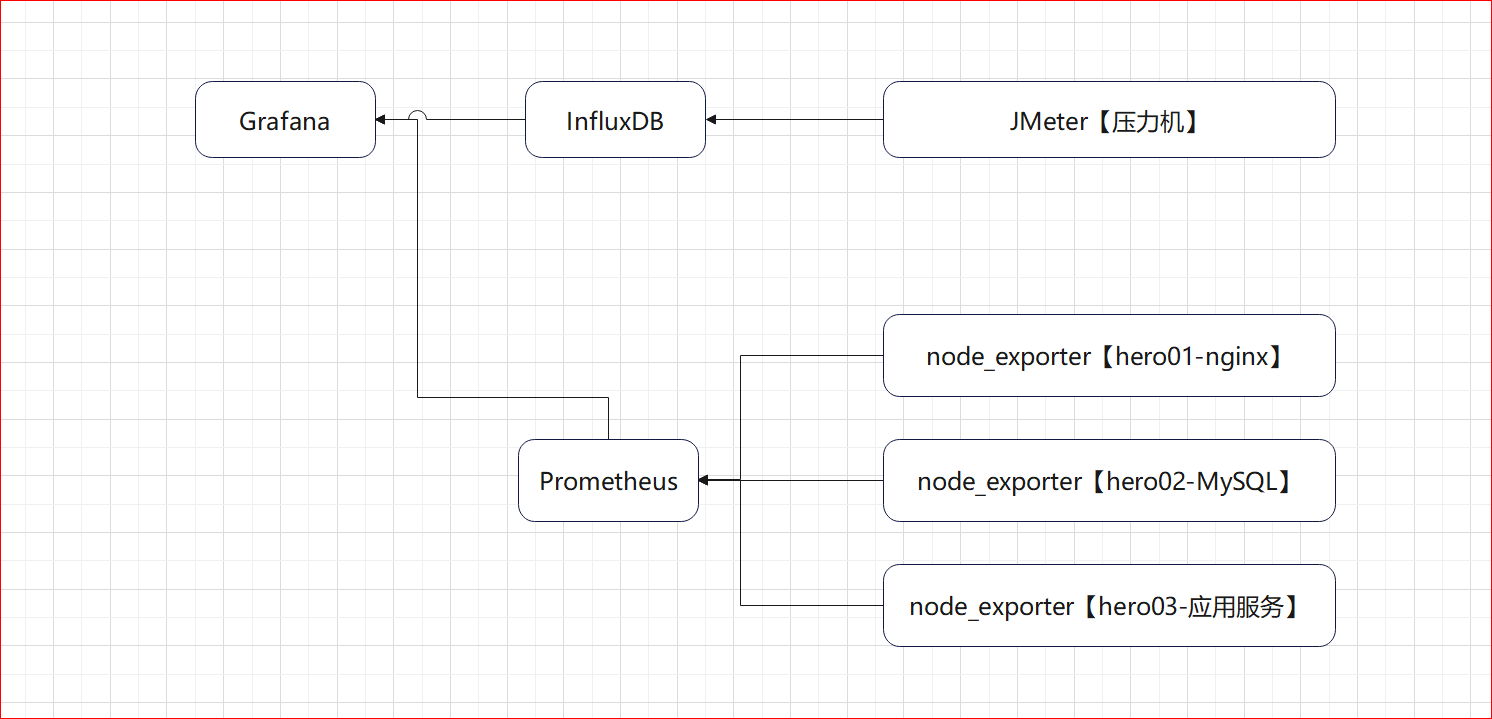
安装InfluxDB
1、下载InfluxDB的镜像
docker pull influxdb:1.82、启动InfluxDB的容器,并将端口 8083 和 8086 映射出来
docker run -d --name influxdb -p 8086:8086 -p 8083:8083 influxdb:1.83、进入容器内部,创建名为jmeter的数据库
进入 jmeter-influx 容器
docker exec -it influxdb /bin/bash输入influx命令,即可进入influx操作界面
输入create database jmeter 命令,创建名为 jmeter 的数据库
输入show databases命令,查看数据库创建成功
root@517f57017d99:/# influx
Connected to http://localhost:8086 version 1.7.10
InfluxDB shell version: 1.7.10
> create database jmeter
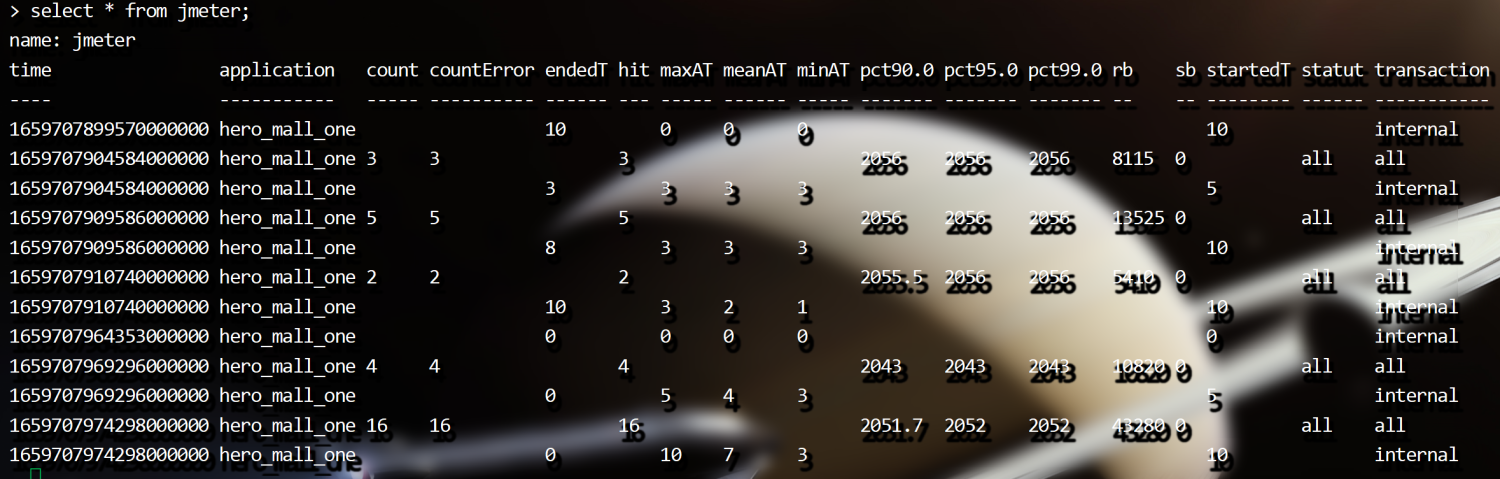
> show databases4、使用JMeter 库, select 查看数据,这个时候是没有数据的
输入use jmeter命令,应用刚才创建的数据库
输入select * from jmeter 命令,查询库中有哪些数据
> use jmeter
> select * from jmeter设置JMeter脚本后置监听器
1、配置后置监听器
想要将 JMeter的测试数据导入 InfluxDB ,就需要在 JMeter中使用 Backend Listener 配置

2、主要配置说明
implementation 选择 InfluxDB所对应的:
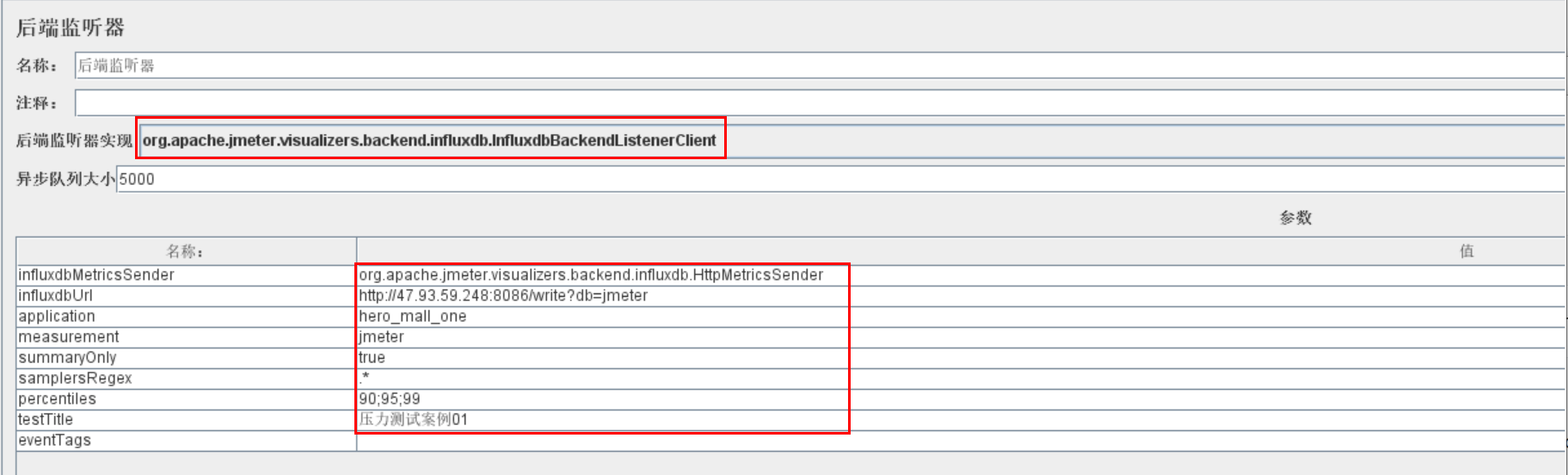
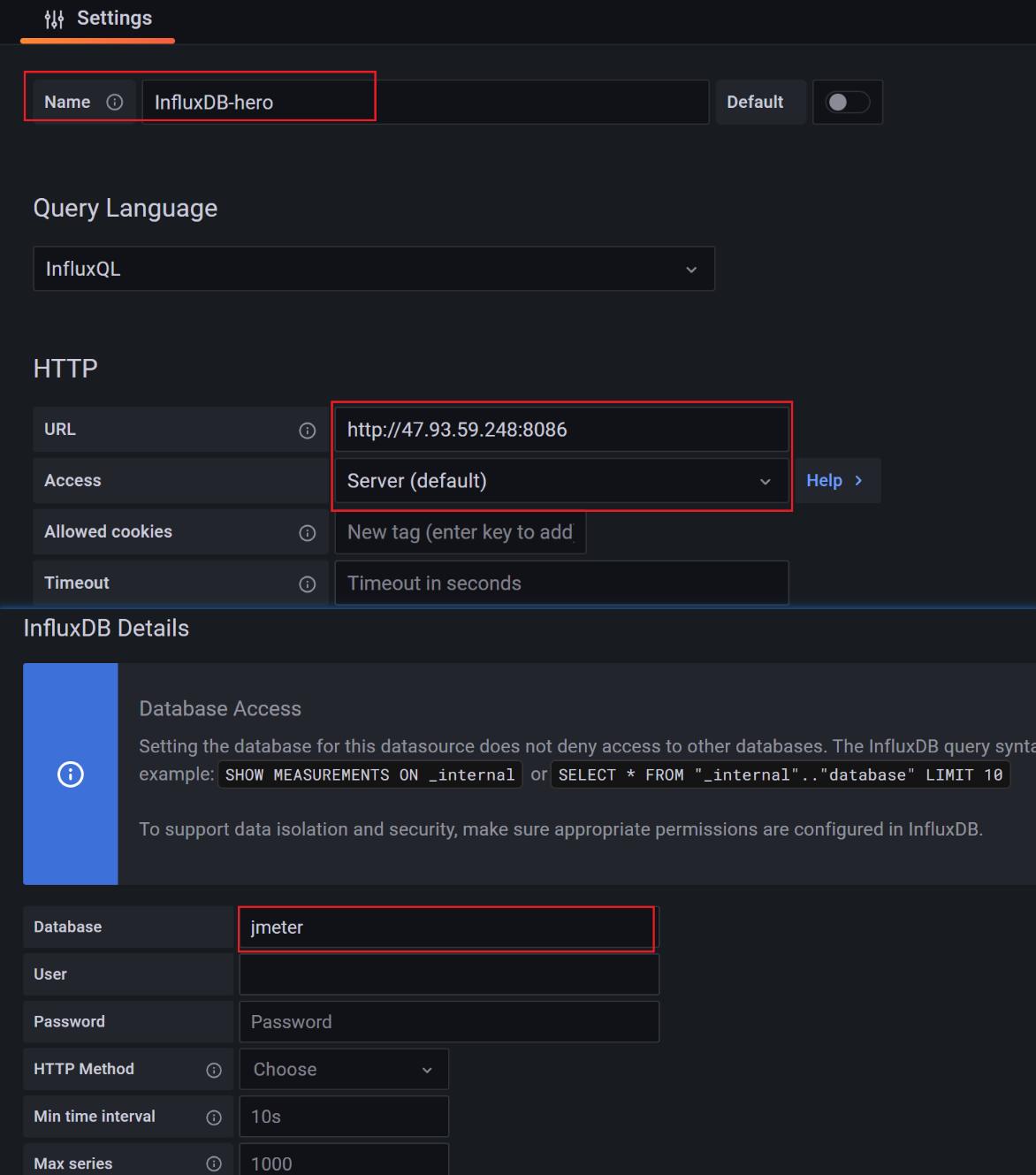
influxdbUrl:需要改为自己influxdb的部署ip和映射端口,我这里是部署在阿里云服务器,所以就是47.93.59.248,口是容器启动时映射的8086端口,db后面跟的是刚才创建的数据库名称
application:可根据需要自由定义,只是注意后面在 grafana 中选对即可
measurement:表名,默认是 jmeter ,也可以自定义
summaryOnly:选择true的话就只有总体的数据。false会记录总体数据,然后再将每个transaction都分别记录
samplersRegex:样本正则表达式,将匹配的样本发送到数据库
percentiles:响应时间的百分位P90、P95、P99
testTitle:events表中的text字段的内容
eventTags:任务标签,配合Grafana一起使用
运行验证
运行一个Jmeter 脚本,然后在 influxdb 中查看数据,发现类似下面的数据说明输入导入成功:
安装Grafana
1、下载Grafana镜像
docker pull grafana/grafana2、启动Grafana容器
启动Grafana容器,将3000端口映射出来
docker run -d --name grafana -p 3000:3000 grafana/grafana3、验证部署成功
网页端访问http://101.200.146.199:3000验证部署成功
默认账户密码:admin\admin
4、选择添加数据源
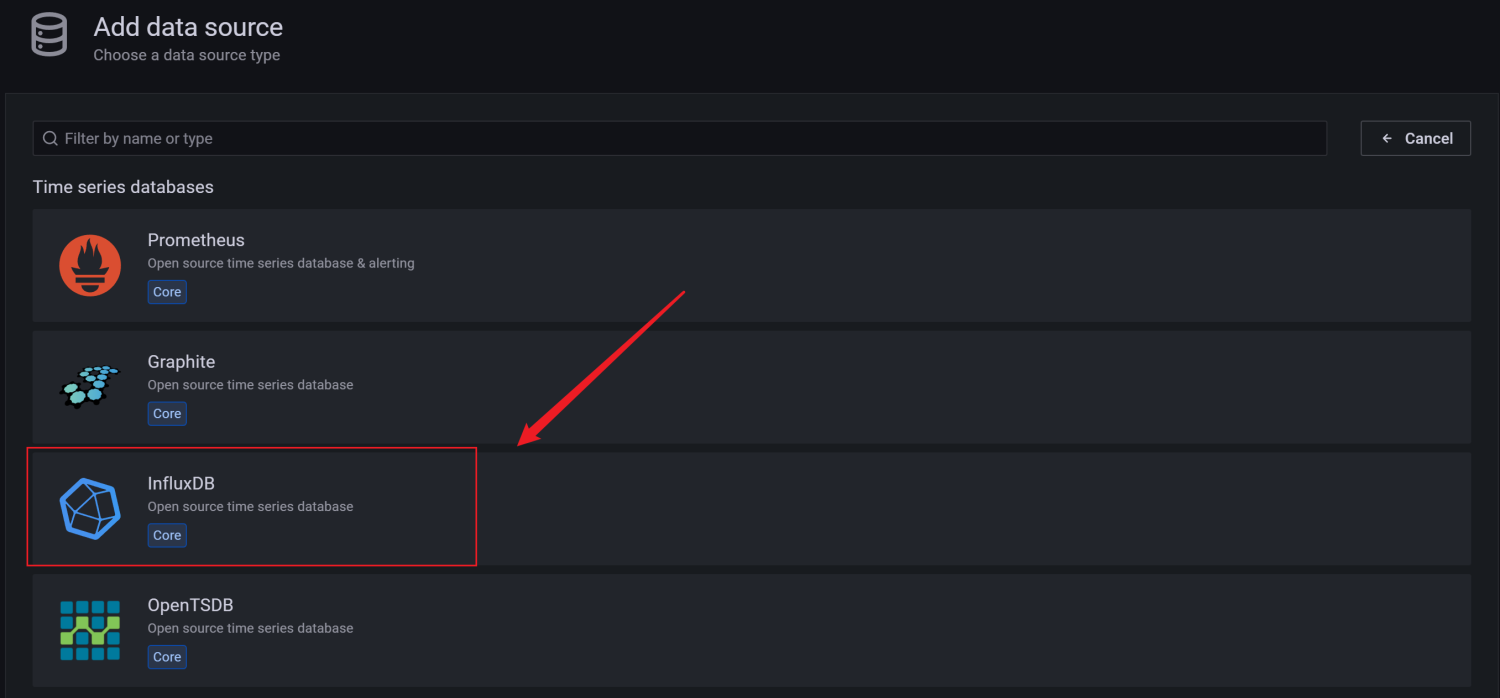
5、找到并选择 influxdb
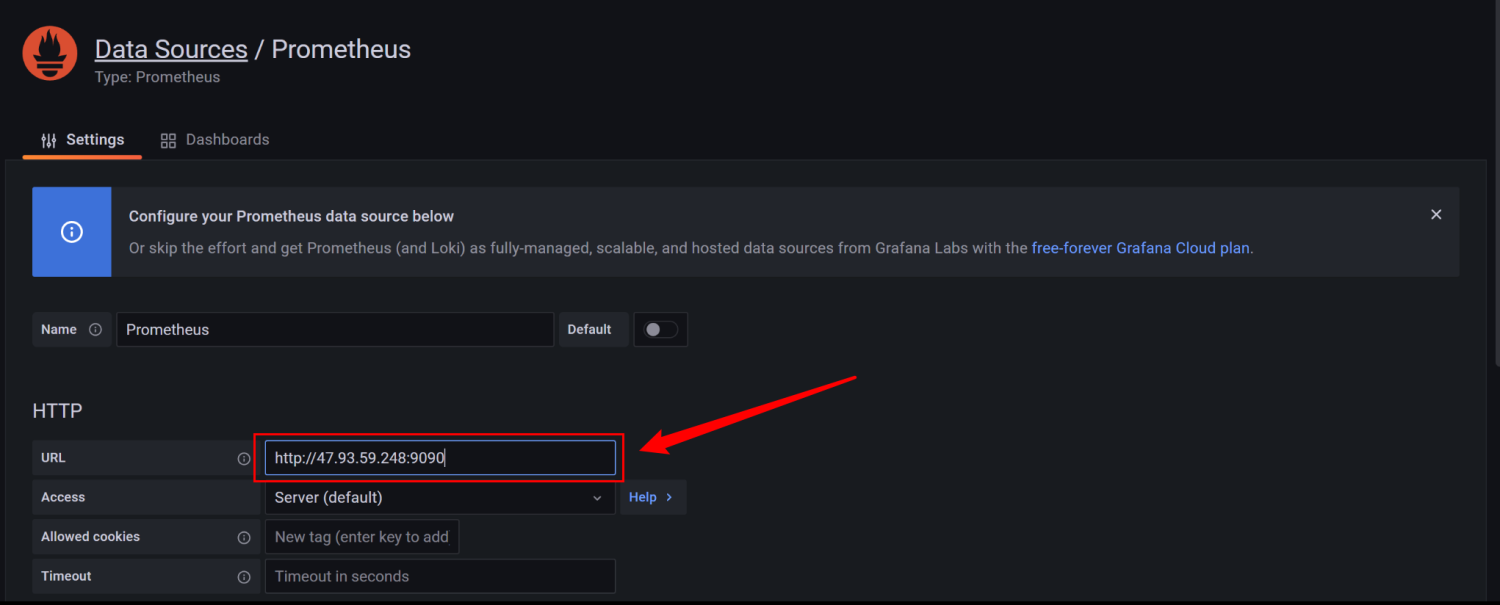
6、配置数据源
数据源创建成功时会有绿色的提示:

7、导入模板
模板导入分别有以下3种方式:
直接输入模板id号
直接上传模板json文件
直接输入模板json内容
8、找展示模板
在Grafana的官网找到我们需要的展示模板
Apache JMeter Dashboard
dashboad-ID:5496
JMeter Dashboard(3.2 and up)
dashboad-ID:3351
9、导入找到的模板,使用模板id
导入模板,我这里选择输入模板id号,导入后如下,配置好模板名称和对应的数据源,然后 import 即可
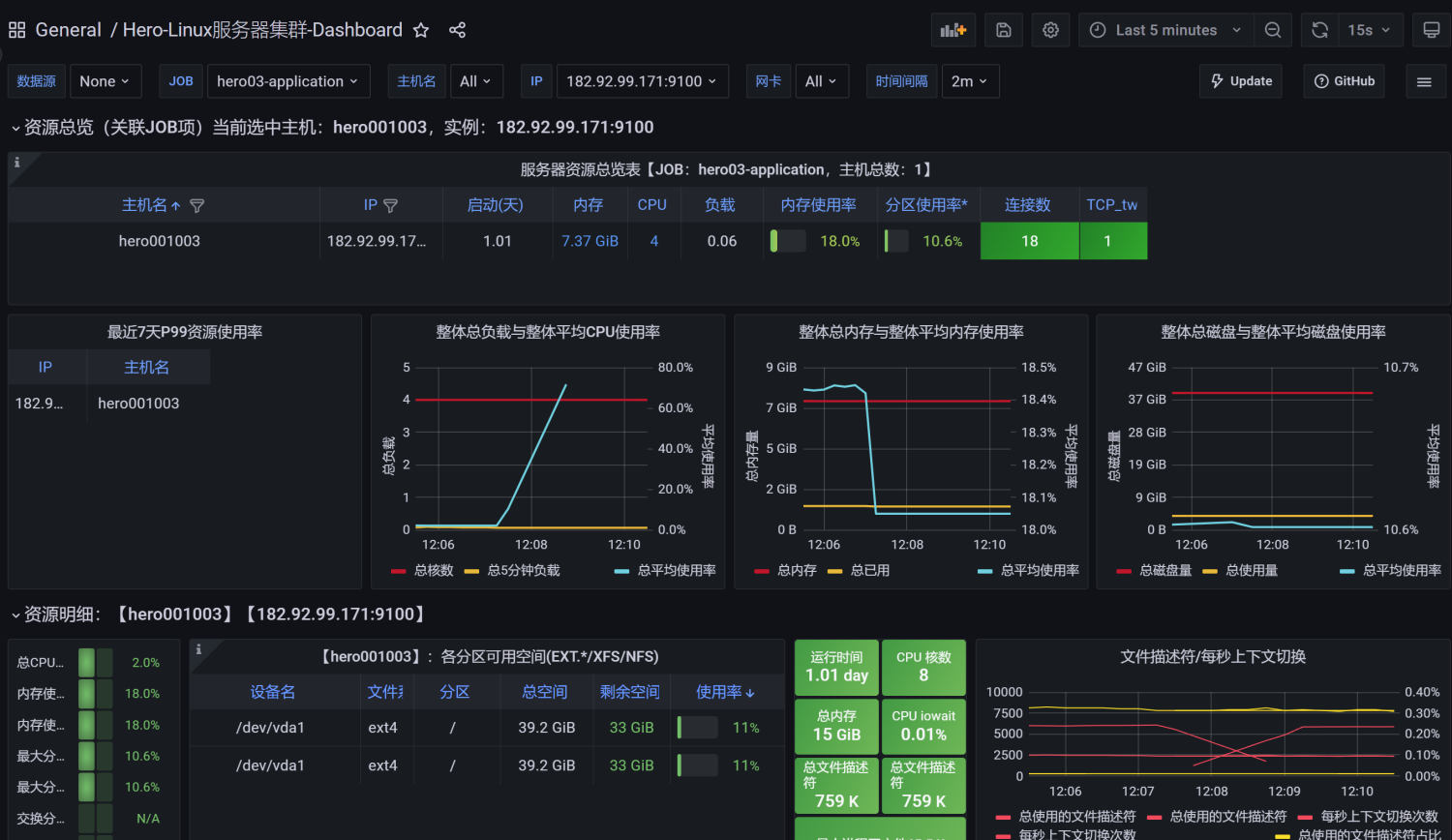
10、查看效果
展示设置,首先选择创建的application
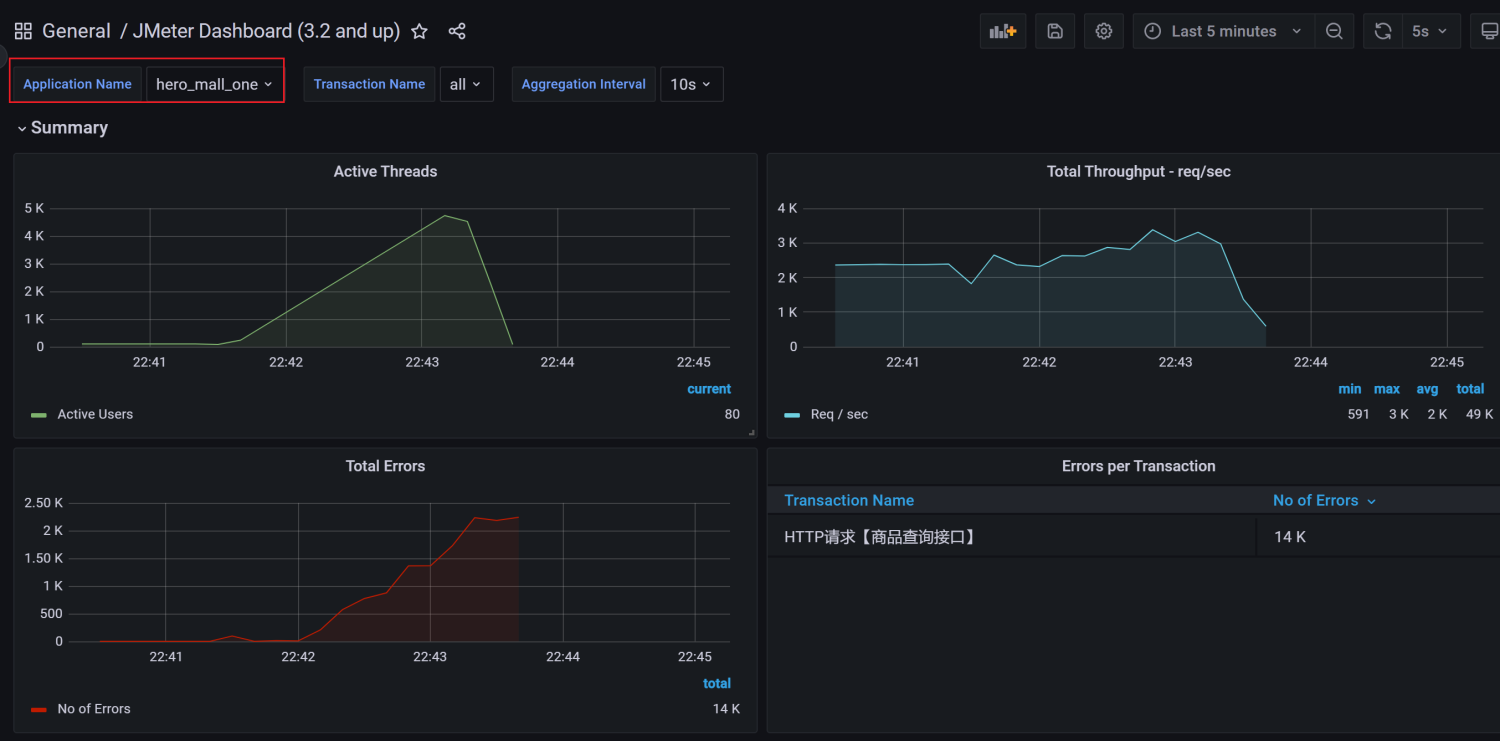
注意: 如果我们修改过表名,也就是在jmeter的Backend Listener的measurement配置(默认为 jmeter),这个时候就需要去设置中进行修改,我这里使用的就是默认的,所以无需修改。
安装node_exporter
node_exporter 主要用于 *NIX 系统监控, 用 Golang 编写。
# 下载
wget -c https://github.com/prometheus/node_exporter/releases/download/v0.18.1/node_ex porter-0.18.1.linux-amd64.tar.gz
# 解压
mkdir /usr/local/hero/ tar zxvf node_exporter-0.18.1.linux-amd64.tar.gz -C /usr/local/hero/
# 启动
cd /usr/local/hero/node_exporter-0.18.1.linux-amd64
nohup ./node_exporter > node.log 2>&1 &注意:在被监控服务器中配置开启端口9100
http://101.200.87.86:9100/metrics

安装Prometheus
1、下载解压运行
# 下载
wget -c https://github.com/prometheus/prometheus/releases/download/v2.15.1/prometheus -2.15.1.linux-amd64.tar.gz
# 解压
tar zxvf prometheus-2.15.1.linux-amd64.tar.gz -C /usr/local/hero/ cd /usr/local/hero/prometheus-2.15.1.linux-amd64
# 运行
nohup ./prometheus > prometheus.log 2>&1 &2、配置prometheus
在prometheus.yml中加入如下配置:
- job_name: 'hero-Linux'
static_configs:
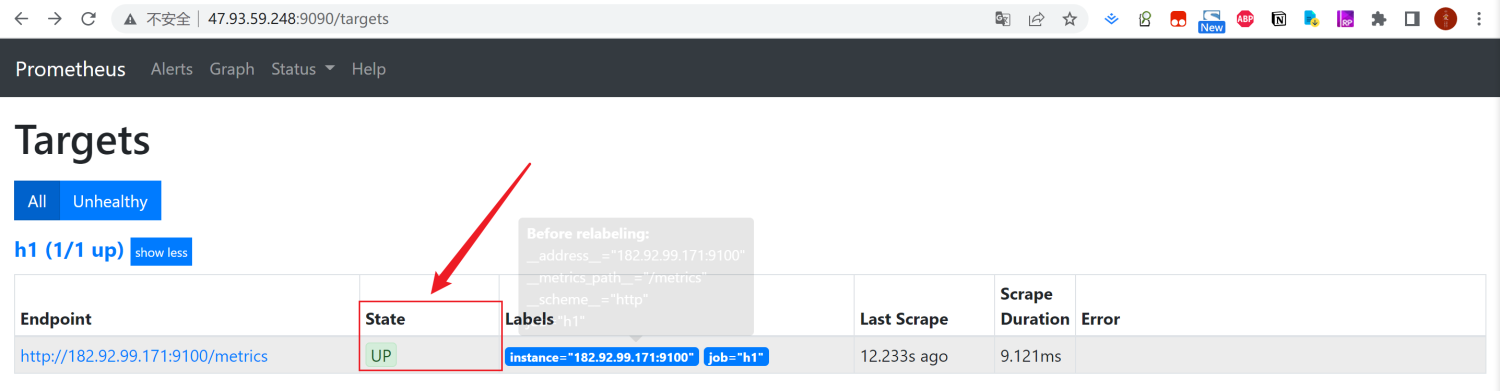
- targets: ['172.17.187.78:9100','172.17.187.79:9100','172.17.187.81:9100']3、测试Prometheus
测试Prometheus是否安装配置成功
http://101.200.146.199:9090/targets
4、在Grafana中配置Prometheus的数据源:
4、Grafana导入Linux展示模板
导入Linux系统dashboard
Node Exporter for Prometheus Dashboard EN 20201010
dashboard-ID: 11074
Node Exporter Dashboard
dashboard-ID: 16098
五、梯度压测
以上主要的四种性能指标【响应时间、并发用户数、吞吐量、资源使用率】它们之间存在一定的相关性,共同反映出性能的不同方面。

压测接口:响应时间20ms,响应数据包3.8kb,请求数据包0.421kb
http://59.110.66.2:9001/spu/goods/10000005620800压测配置
情况01-模拟低延时场景,用户访问接口并发逐渐增加的过程。
预计接口的响应时间为20ms
线程梯度:5、10、15、20、25、30、35、40个线程
循环请求次数5000次
时间设置:Ramp-up period(inseconds)的值设为对应线程数
测试总时长:约等于20ms x 5000次 x 8 = 800s = 13分
配置断言:超过3s,响应状态码不为20000,则为无效请求
机器环境
应用服务器配置:4C8G
外网-网络带宽25Mbps (峰值)
内网-网络带宽基础1.5/最高10Gbit/s
集群规模:单节点
服务版本:v1.0
数据库服务器配置:4C8G
配置监听器
聚合报告:添加聚合报告
查看结果树:添加查看结果树
活动线程数:压力机中活动的线程数
TPS统计分析:每秒事务树
RT统计分析:响应时间
后置监听器,将压测信息汇总到InfluxDB,在Grafana中呈现
压测监控平台:
JMeter DashBoard
应用服务器:内存、网络、磁盘、系统负载情况
MySQL服务器:内存、网络、磁盘、系统负载情况
性能瓶颈剖析
梯度压测,测出瓶颈
进一步提升压力,发现性能瓶颈
使用线程:5,然后循环5000次,共2.5万个样本
使用线程:10,然后循环5000次,共5万个样本
使用线程:15,然后循环5000次,共7.5万个样本
使用线程:20,然后循环5000次,共10万个样本
使用线程:25,然后循环5000次,共12.5万个样本
使用线程:30,然后循环5000次,共15万个样本
使用线程:35,然后循环5000次,共17.5万个样本
使用线程:40,然后循环5000次,共20万个样本
聚合报告

Active Threads
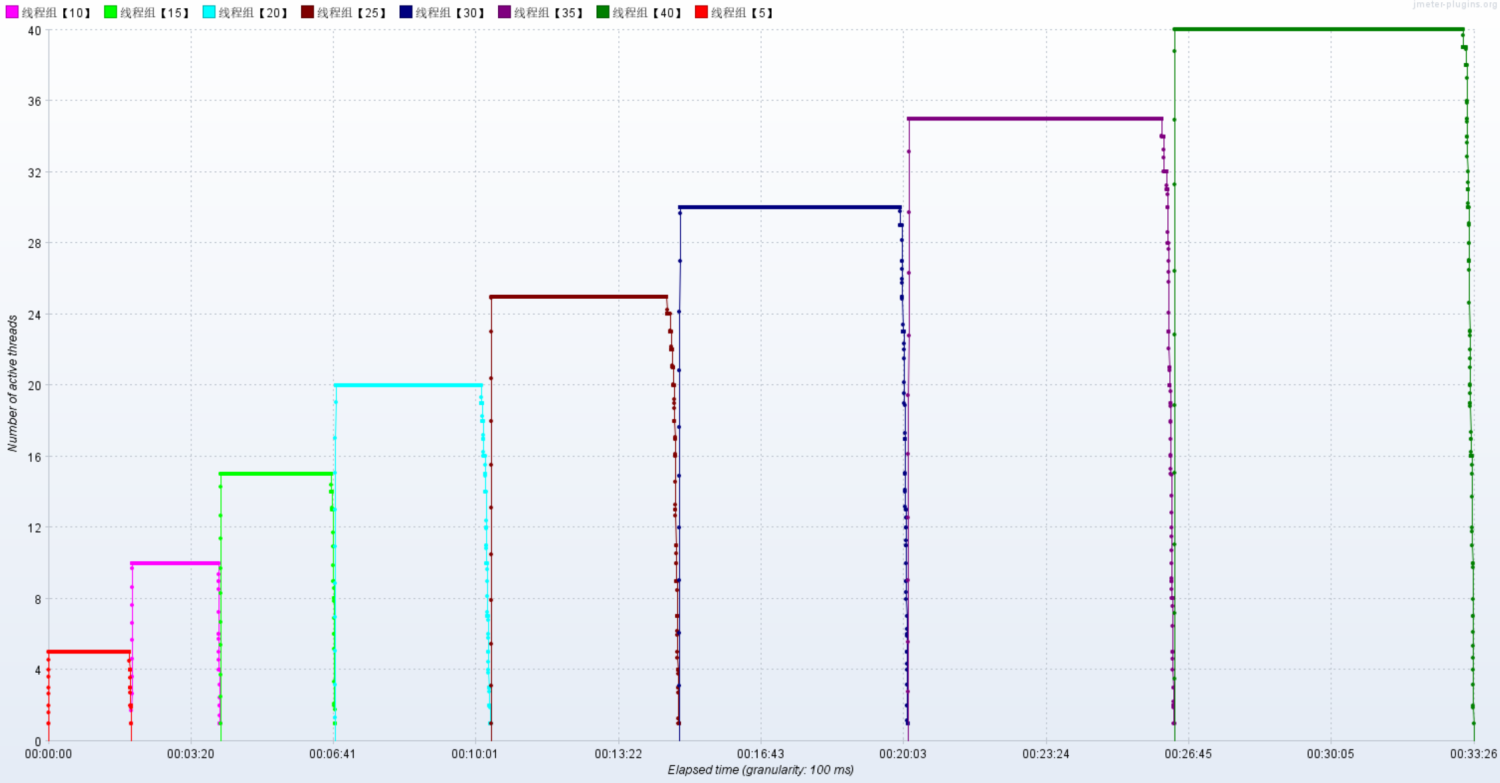
RT
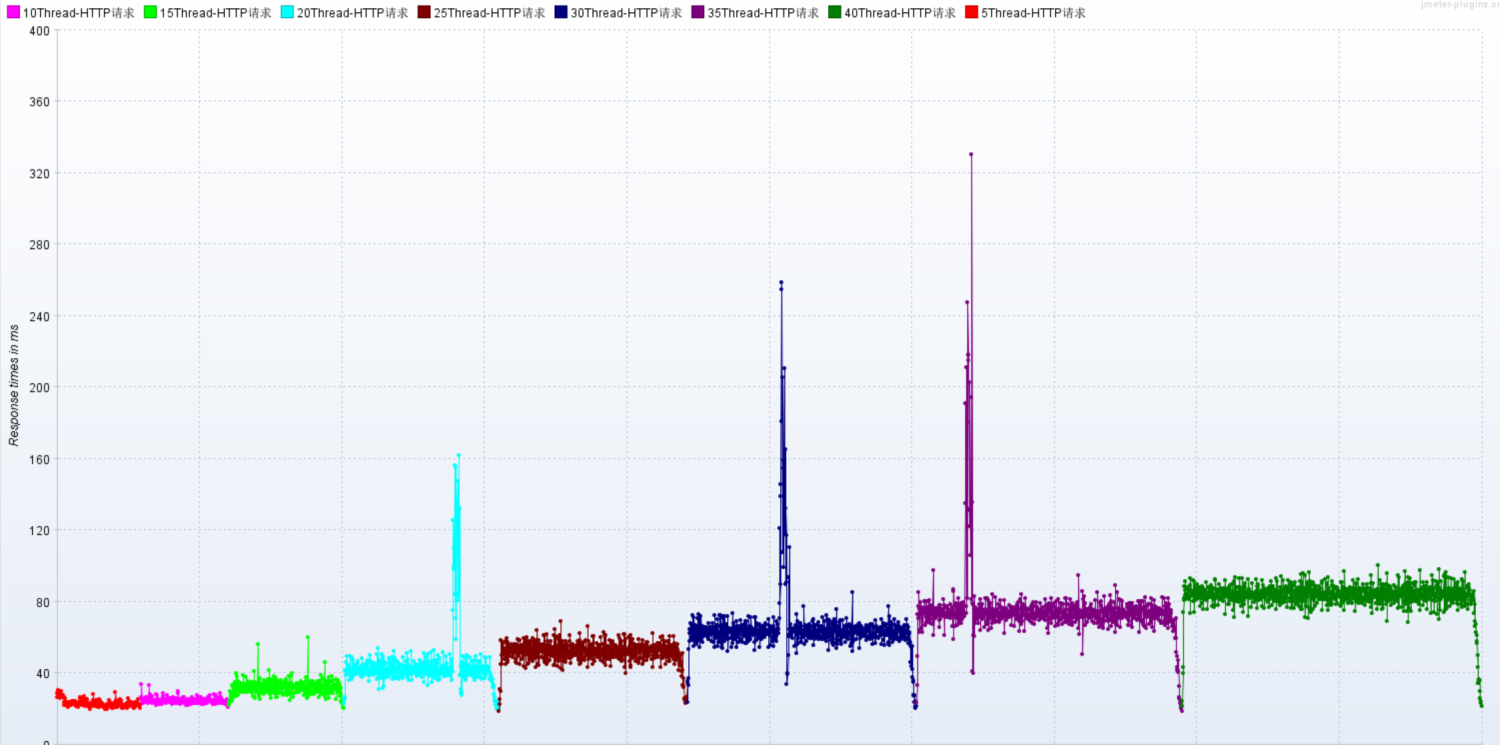
TPS
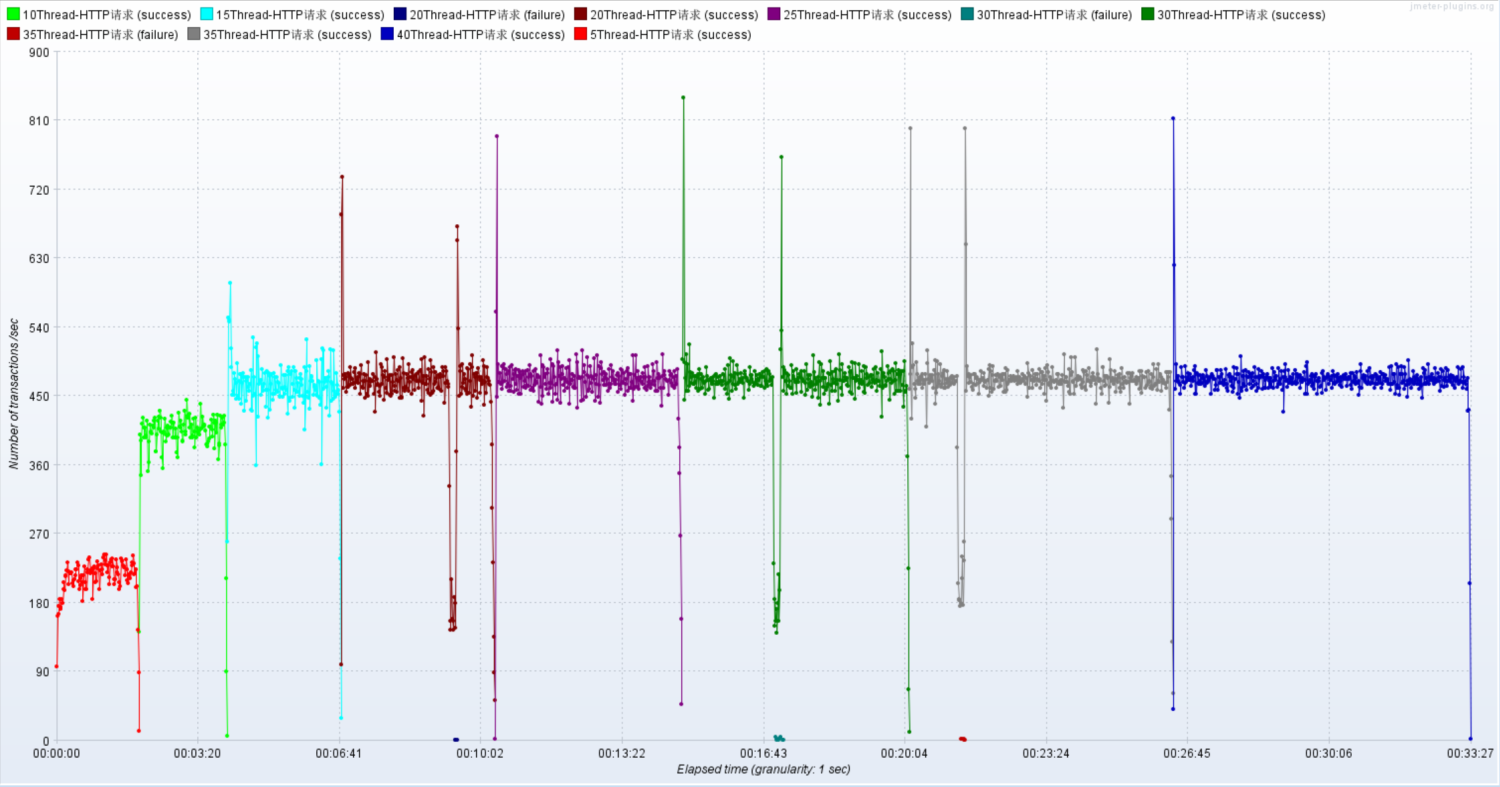
压测监控平台与JMeter压测结果一致
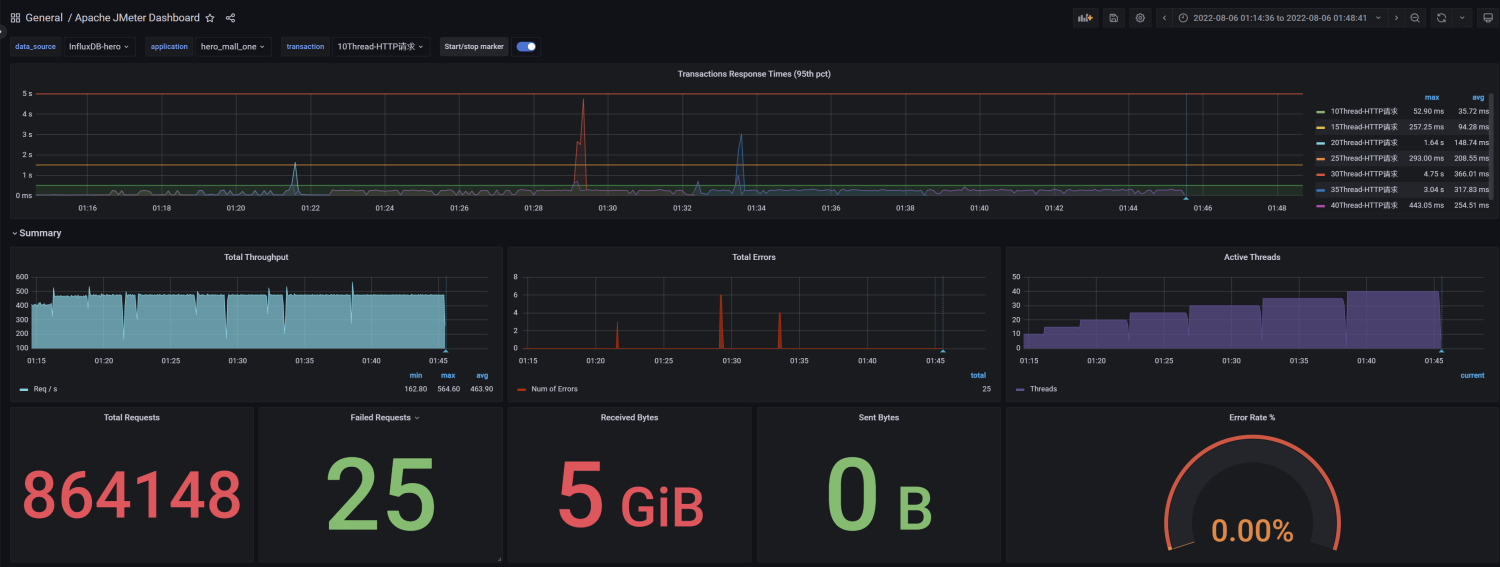
压测中服务器监控指标
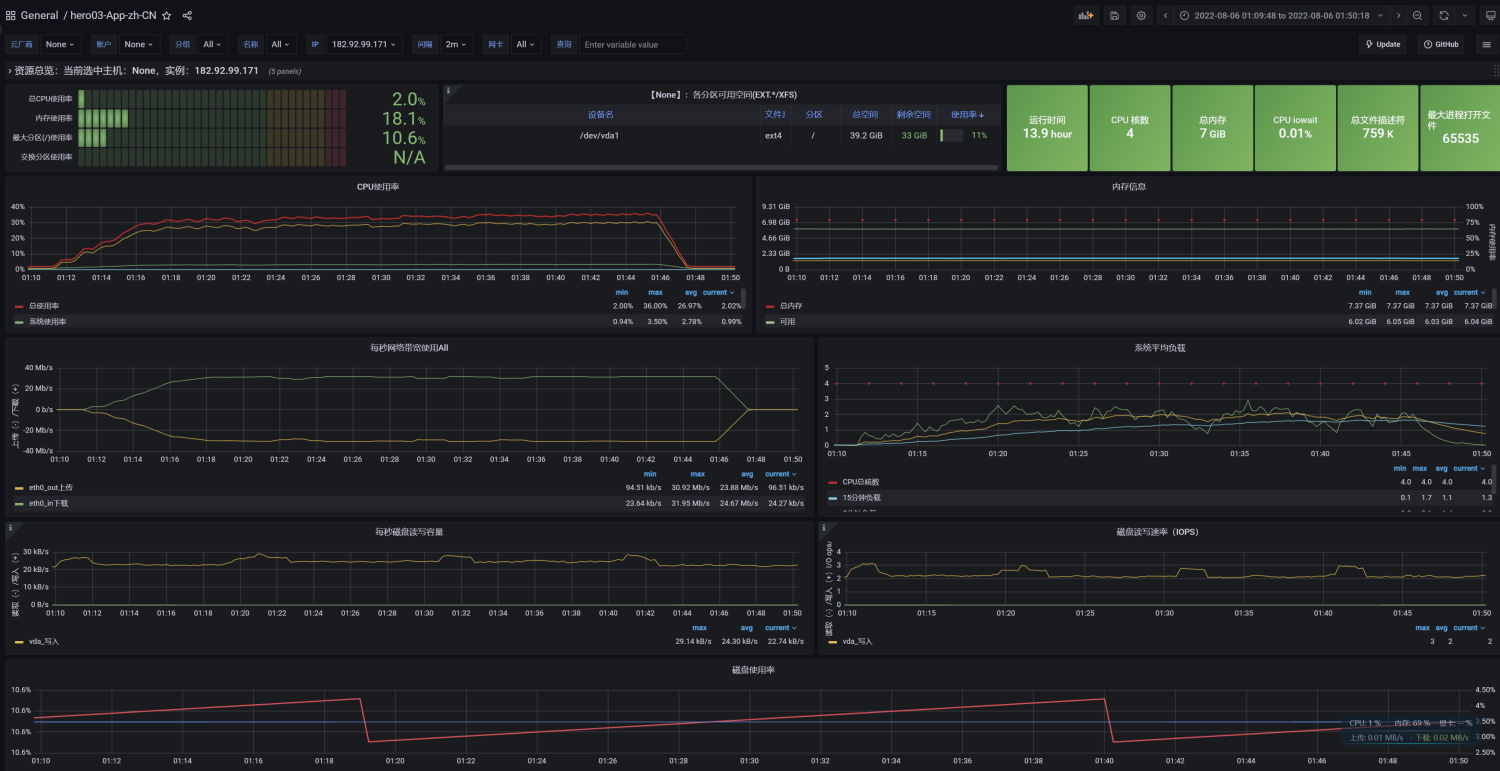
问题1:网络到达瓶颈
注意:系统网络带宽为25Mbps
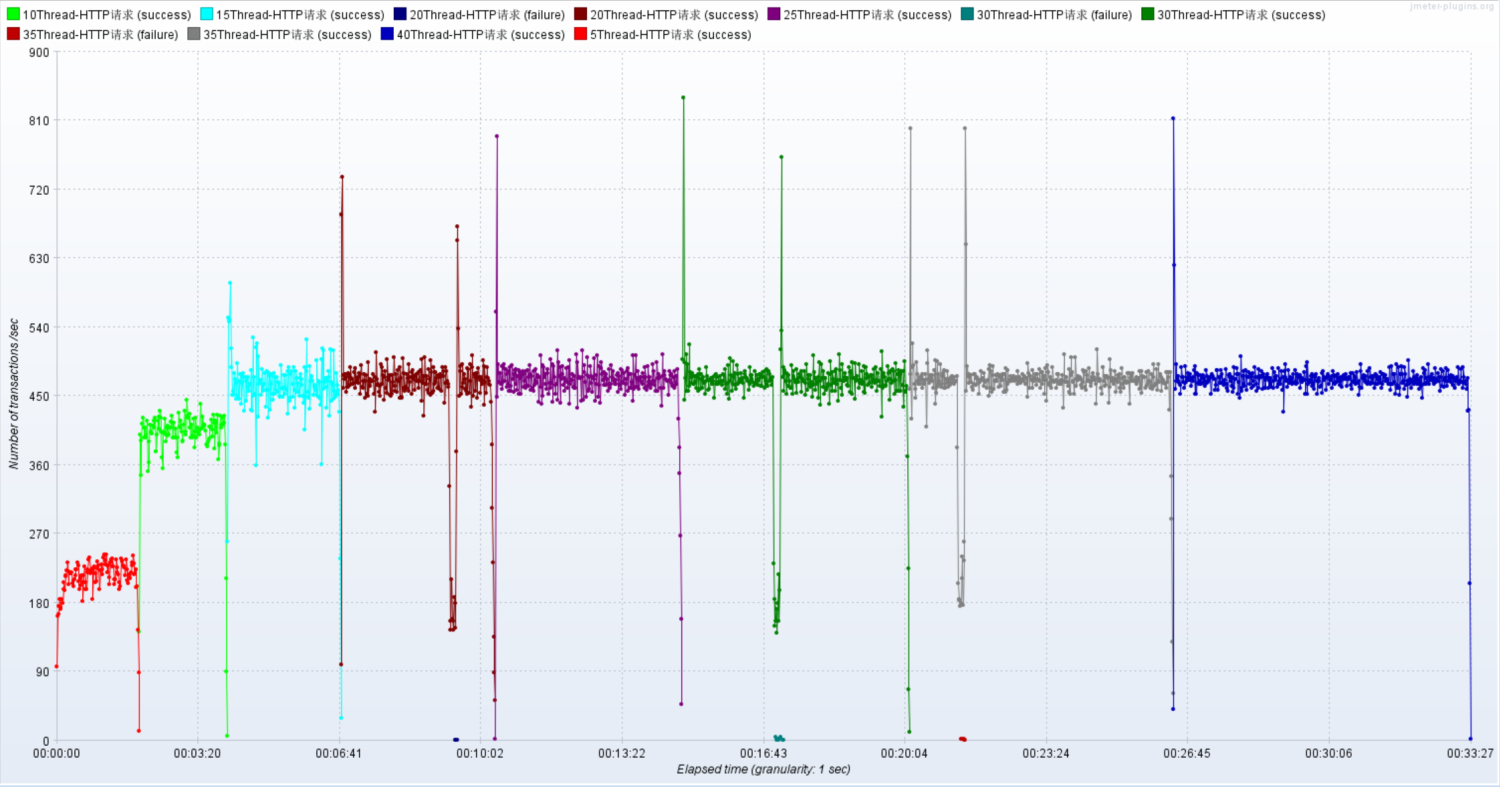
结论:随着压力的上升,TPS不再增加,接口响应时间逐渐在增加,偶尔出现异常,瓶颈凸显。系统的 负载不高。CPU、内存正常,说明系统这部分资源利用率不高。带宽带宽显然已经触顶了。
优化方案:
方案01-降低接口响应数据包大小
方案02-提升带宽【或者在内网压测】
优化之后:
方案01-降低接口响应数据包大小,压测结果



结论:
在低延时场景下,服务瓶颈主要在服务器带宽。
TPS数量等于服务端线程数 乘以 (1000ms/ RT均值)
RT=21ms,TPS=800,服务端线程数:= 800/ (1000ms/ RT均值) = 17
问题2:接口的响应时间是否正常?是不是所有的接口响应都可以这么快?
情况02-模拟高延时场景,用户访问接口并发逐渐增加的过程。接口的响应时间为500ms,
线程梯度:100、200、300、400、500、600、700、800个线程;
循环请求次数200次
时间设置:Ramp-up period(inseconds)的值设为对应线程数的1/10;
测试总时长:约等于500ms x 200次 x 8 = 800s = 13分
配置断言:超过3s,响应状态码不为20000,则为无效请求
//慢接口
@GetMapping("/goods/slow/{spuId}")
public Result findGoodsBySpuIdTwo(@PathVariable String spuId) {
Goods goods = spuService.findBySpuId(spuId); //模拟慢接口
try { //休眠500ms
TimeUnit.MILLISECONDS.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
return new Result(true, StatusCode.OK, "查询成功", goods);
}响应慢接口:500ms+,响应数据包3.8kb,请求数据包0.421kb
http://59.110.66.2:9001/spu/goods/slow/10000005620800测试结果:RT、TPS、网络IO、CPU、内存、磁盘IO

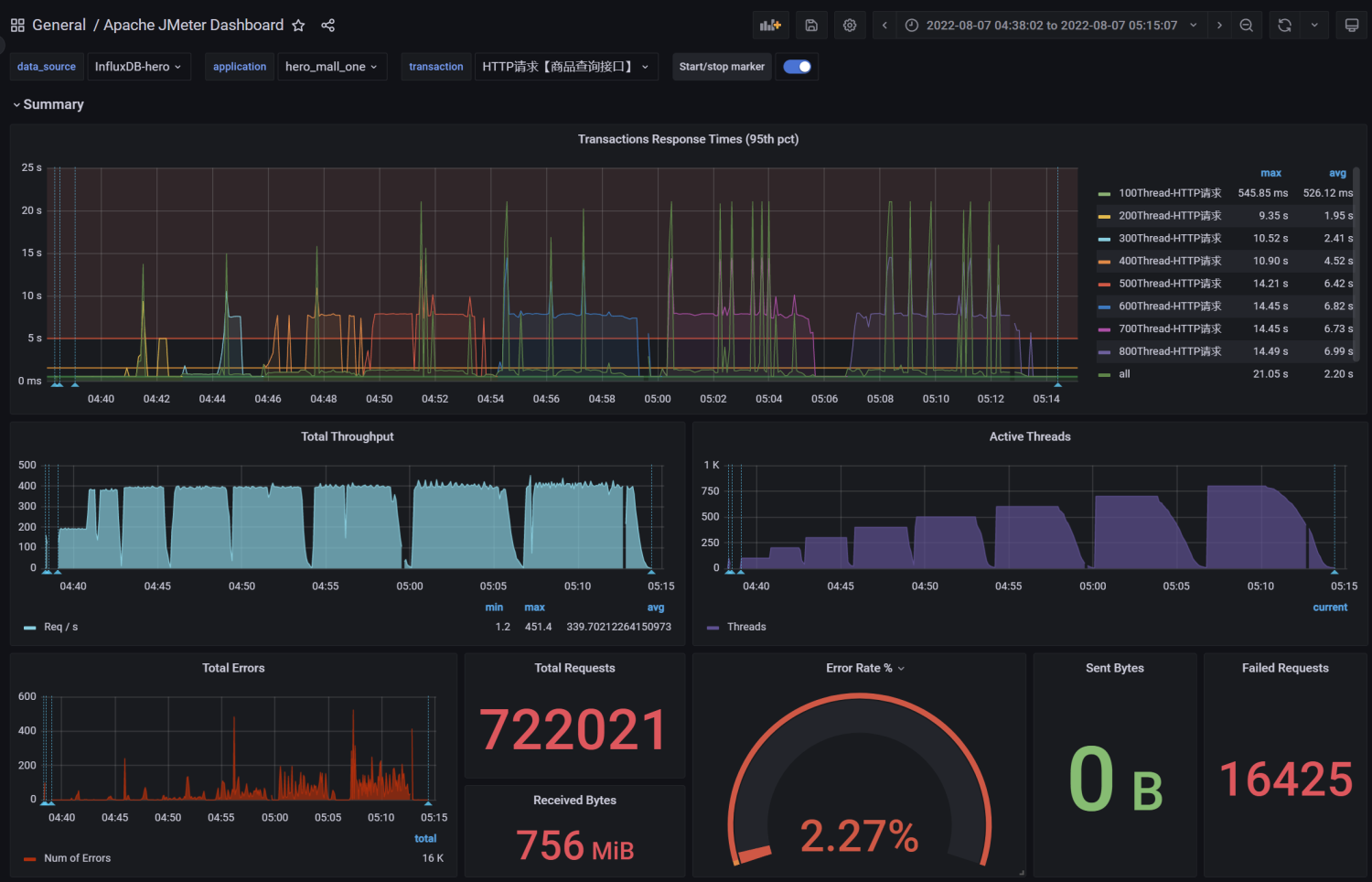
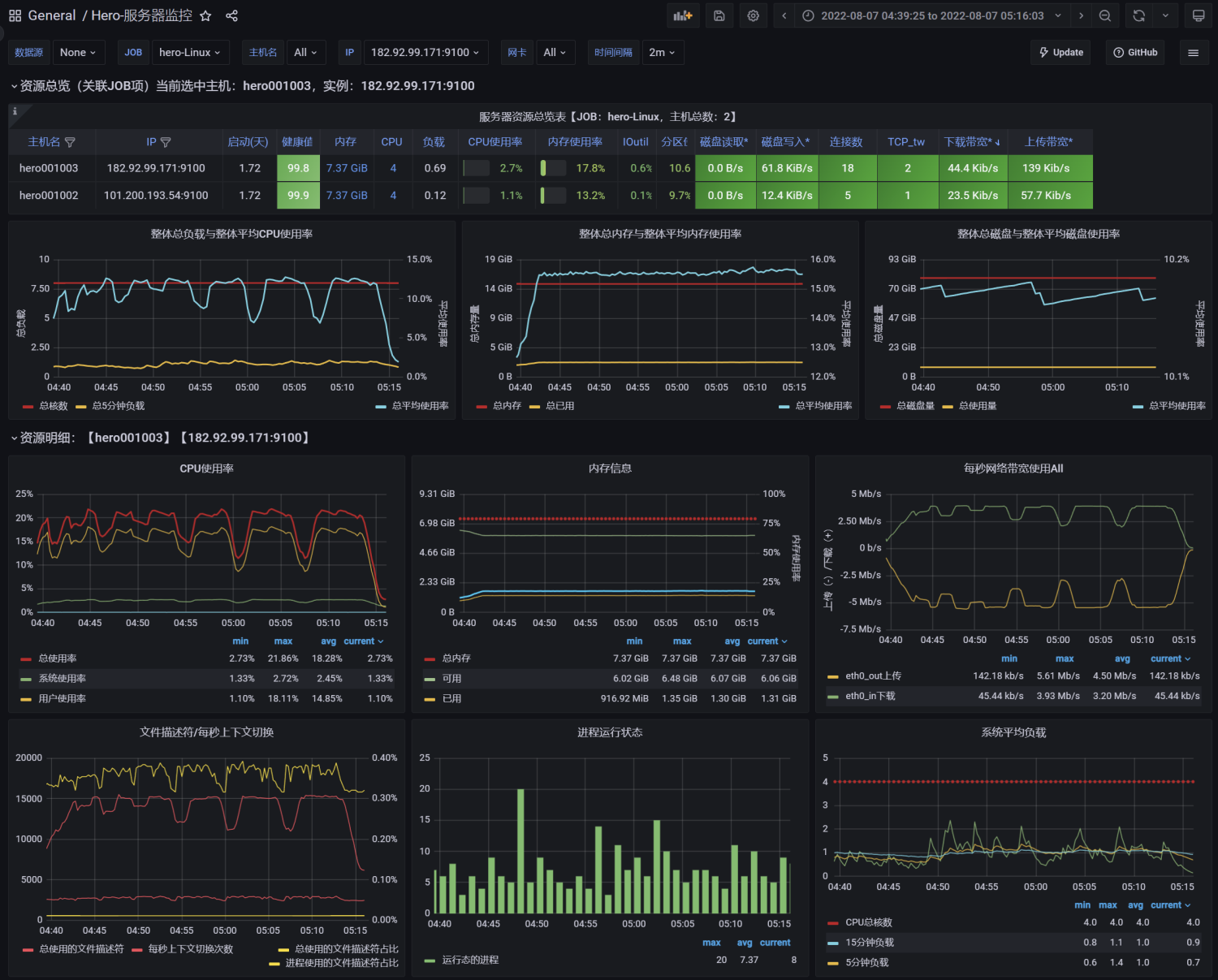
结论:
在高延时场景下,服务瓶颈主要在容器最大并发线程数。
RT=500ms,TPS=800,服务端线程数:= 800/ (1000ms/ RT) = 400(Tomcat默认的最大的线程数?200)
观察服务容器最大线程数,发现处理能力瓶颈卡在容器端
问题3:TPS在上升到一定的值之后,异常率较高
可以理解为与IO模型有关系,因为当前使用的是阻塞式IO模型。
这个问题可以通过优化容器部分解决,比如更换IO模型、将tomcat更换成undertow等。
学习视频资源分享:性能优化之服务压测

