



Elasticsearch入门
如果还未安装Elasticsearch,推荐参考这篇博客通过docker安装测试环境:Elasticsearch环境与搭建#Docker-Compose 单机部署(个人测试推荐使用)
RESTful & JSON
Elasticsearch使用RESTful风格的http请求进行通信(操作索引、添加数据、修改数据、删除数据等),通过JSON数据格式传递数据。
所谓的RESTful,就是通过一个URI(Universal Resource Identifier)标识网络上的一个资源,再通过HTTP Method标识操作类型。
比如,https://localhost:9200/employee/123 标识了id为123的某个员工,则:
- Post请求表示添加id为123的员工信息
POST https://localhost:9200/employee/123
{
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": [
"sports",
"music"
]
}
- Get请求表示获取id为123的员工信息
GET https://localhost:9200/employee/123
- Put请求表示修改id为123的员工信息
PUT https://localhost:9200/employee/123
{
"age": 27
}
- Delete请求表示删除id为123的员工信息
DELETE https://localhost:9200/employee/123
Elasticsearch概念介绍
Elasticsearch是面向文档型的数据库,一条数据就是一个文档。为了方便理解,这里将Elasticsearch的结构和MySQL的结构做一个类比。
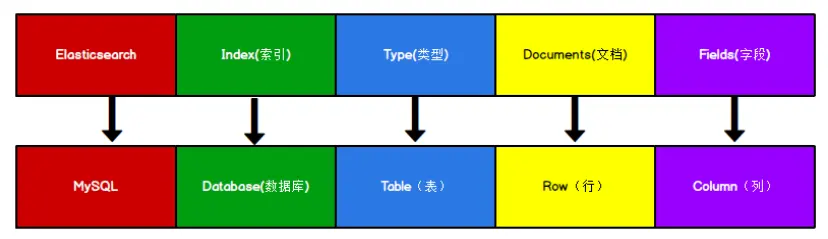
ES中的Index可以看做一个库,而Typpes相当于表,Documents则相当于表的一行数据。
这里Types的概念已经被逐渐弱化,在Elasticsearch 6.X中,一个 index 下已经只能包含一个type, Elasticsearch 7.X 中, Type 的概念已经被删除了。
倒排索引
要理解什么事倒排索引,首先要了解什么是正排索引。
正排索引
假如在MySQL的某个表中有以下数据:
| id | content |
|---|---|
| 1001 | My name is zhang san. |
| 1002 | My name is li si. |
所谓的正排索引就是我们一直以来习惯的通过id找到文章内容,比如通过id=1001查询到content内容。
在正排索引中,如果我们要查询某个列包含了某个关键字的数据,则需要使用MySQL的like关键字进行模糊查询,比如select * from table where content like '%zhang%';。
但我们都知道,MySQL前后模糊查询的效率是非常慢的。
倒排索引
而倒排索引则不一样,在保存数据时,ES先将需要索引的内容进行分词,然后记录每个单词对应的id。
比如My name is zhang san可以按照规则被分词为:name、zhang、san三个词,而这三个词都关联了id=1001;My name is li si按照规则被分词为:name、li、si,这三个词都关联了id=1002。
那么在ES中将会以下面的形式进行存储:
| keyword | id |
|---|---|
| name | 1001,1002 |
| zhang | 1001 |
| san | 1001 |
| li | 1002 |
| si | 1002 |
此时通过zhang关键字在keyword中很快就能查出关联了1001一个id。
HTTP操作数据
这里使用的kibana的开发工具,所以只展示了http method和url path部分,如果想通过postman或apifox等工具发送请求,则填写完整的url并选择对应的http method即可。
索引操作
1)创建索引
PUT /shopping
2)查询索引信息
GET /shopping
4)删除索引
DELETE /shopping
文档操作
1)添加文档
不指定id则会给这条数据生成一个随机id
POST /shopping/_doc
{
"title": "小米手机",
"category": "手机",
"images": "https://img.flycat.tech/common/avatar.jpg",
"price": 3999.00
}
或者
PUT /shopping/_doc
{
"title": "小米手机",
"category": "手机",
"images": "https://img.flycat.tech/common/avatar.jpg",
"price": 3999.00
}
指定id则使用指定的id
POST /shopping/_doc/1001
{
"title": "小米手机",
"category": "手机",
"images": "https://img.flycat.tech/common/avatar.jpg",
"price": 3999.00
}
或者
PUT /shopping/_doc/1001
{
"title": "小米手机",
"category": "手机",
"images": "https://img.flycat.tech/common/avatar.jpg",
"price": 3999.00
}
2)查询文档
根据id查询
GET /shopping/_doc/1001
查询全部
GET /shopping/_search
3)修改文档
覆盖更新
POST或PUT /shopping/_doc/1001
{
"title": "小米手机",
"category": "手机",
"images": "https://img.flycat.tech/common/avatar.jpg",
"price": 4999.00
}
局部更新
POST /shopping/_update/1001
{
"doc": {
"price": 2999.00
}
}
覆盖更新和局部更新的区别是什么?
当使用覆盖更新时,则需要携带所有字段的数据,否则没有携带数据的字段的数据就会丢失。
比如id为1001在数据库中的数据为
{ "title": "小米手机", "category": "手机", "images": "https://img.flycat.tech/common/avatar.jpg", "price": 4999.00 }此时使用覆盖更新,但是只携带了price字段,更新语句如下:
POST /shopping/_doc/1001 { "price": 2999.00 }那么此时id为1001在数据库中的数据就变成了只有一个price字段的文档:
{ "price": 2999.00 }
4)删除文档
DELETE /shopping/_doc/1001
5)条件查询
完全匹配查询
# 查询category为“手机”的所有数据
GET /shopping/_search
{
"query": {
"match_phrase": {
"category": "手机"
}
}
}
全文检索查询
# 搜索title中含有“手机”关键词的数据
GET /shopping/_search
{
"query": {
"match": {
"title": "手机"
}
}
}
完全匹配和全文检索使用的关键字分别是match_phrase和match,这两者不同之处在于,match_phrase是精确匹配某个关键字,在上一个例子中就是查询category="手机"的数据,多一个字少一个字都不行。
而全文检索在查询时,会先根据分词规则将待查询数据进行分词,分词效果取决于分词器。
如果使用了ES默认的分词器,由于则其可能会把“手机”分成“手”和“机”两个词,那么查询出来的结果就是包含“手”或者包含“机”的所有数据。
分页操作
# 从索引0开始,查询10条数据
GET /shopping/_search
{
"from": 0,
"size": 10
}
分页计算通用公式:from = (页码 - 1) * 每页大小
指定查询字段
# 查询所有数据,并只返回title字段
GET /shopping/_search
{
"_source": ["title"]
}
结果排序
# 查询所有数据,并指定price字段降序排序
GET /shopping/_search
{
"sort": [
{
"price": {
"order": "desc"
}
}
]
}
多条件查询
# 多条件查询公式
GET /shopping/_search
{
"query": {
"bool": {
"must|must_not|should": [
{
"match|match_all|match_phrase": {
"FIELD": "TEXT"
}
}
],
"filter": [
{
"range": {
"FIELD": {
"gt|gte|lt|lte": "VALUE"
}
}
}
]
}
}
}
关键字解释
- "FIELD":公式中出现的"FIELD"为文档字段
- "TEXT":公式中出现的"TEXT"为条件输入的文本
- "VALUE":公式中出现的"VALUE"为条件输入的数值类型的数据
- must:must关键字下面的多个查询条件为或关系
- should:should关键字下面的多个查询条件为或关系
- filter:filter关键字用于过滤数据
- range:range用来范围查询,其中gt=大于,gte=大于等于,lt=小于,lte=小于等于
查询示例
# 查询价格必须为2999的数据
GET /shopping/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"price": "2999"
}
}
]
}
}
}
# 查询价格必须为2999且title必须为“小米手机”的数据
GET /shopping/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"price": "2999"
}
},
{
"match": {
"title": "小米手机"
}
}
]
}
}
}
# 查询价格必须为2999或title必须为“小米手机”的数据
GET /shopping/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"price": "2999"
}
},
{
"match": {
"title": "小米手机"
}
}
]
}
}
}
# 查询价格大于等于3000小于等于4000的数据
GET /shopping/_search
{
"query": {
"bool": {
"filter": [
{
"range": {
"price": {
"gte": 3000,
"lte": 4000
}
}
}
]
}
}
}
高亮显示
# 对结果中title字段高亮显示查询的关键字
GET /shopping/_search
{
"query": {
"match": {
"title": "小米"
}
},
"highlight": {
"fields": {
"title": {}
}
}
}
6)聚合查询
# 聚合查询公式
GET /shopping/_search
{
"aggs": {
"NAME": {
"terms|max|min|sum|avg": {
"field": "FIELD",
"size": 10
}
}
},
"size": 0
}
关键字解释
- "NAME":名称,会在查询结果中展示改名称对应的聚合结果
- terms:根据指定的字段进行分组
- max|min|sum|avg:最大值或最小值或求和或求平均值
- 外层的size:如果只需要聚合查询结果而不需要数据,则可以设为0
查询示例
# 根据price字段进行分组
GET /shopping/_search
{
"aggs": {
"price_group": {
"terms": {
"field": "price",
"size": 10
}
}
},
"size": 0
}
映射操作
映射类似于MySQL的scheme(表结构),其定义了有哪些字段以及每个字段的类型等
与MySQL必须先定义scheme不同,在ES中如果没有预先定义映射,在插入数据时,ES会判断当前映射有没有对应字段信息,如果没有则会根据字段的值推断。
当然更推荐的是预先定义好映射信息。
定义映射
PUT /shopping/_mapping
{
"properties": {
"category": {
"type": "keyword",
"index": true,
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"price": {
"type": "float",
"index": true
},
"title": {
"type": "text",
"index": true,
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
关键字解释
- type:字段类型,keyword表示关键字,不进行分词;text表示该字段可被分词
- index:为true则表示该字段可被索引,为false则不可出现在查询条件中
查询映射
跟查询索引相同,结果中包含了映射信息
GET /shopping

