



八股文系列——计算机网络
计算机分层理论
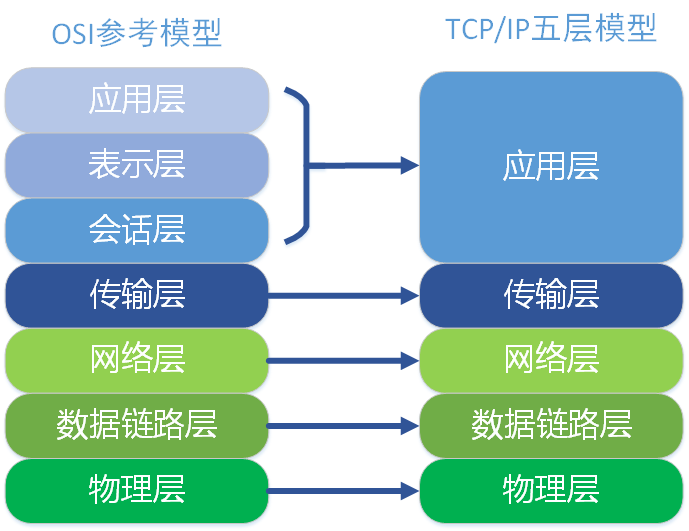
OSI七层网络模型
- 应用层
- 表示层
- 会话层
- 传输层
- 网络层
- 数据链路层
- 物理层
TCP/IP四层网络模型
- 应用层
- 传输层
- 网络层
- 网络接口层
五层网络模型
- 应用层
- 传输层
- 网络层
- 数据链路层
- 物理层
七层网络模型和五层网络模型对比
为什么要分层
- 各层之间相互独立:各层之间相互独立,各层之间不需要关心其他层是如何实现的,只需要知道自己如何调用下层提供好的功能就可以了(可以简单理解为接口调用)。这个和我们对开发时系统进行分层是一个道理。
- 提高了灵活性和可替换性:每一层都可以使用最适合的技术来实现,你只需要保证你提供的功能以及暴露的接口的规则没有改变就行了。并且,每一层都可以根据需要进行修改或替换,而不会影响到整个网络的结构。这个和我们平时开发系统的时候要求的高内聚、低耦合的原则也是可以对应上的。
- 大问题化小:分层可以将复杂的网络问题分解为许多比较小的、界线比较清晰简单的小问题来处理和解决。这样使得复杂的计算机网络系统变得易于设计,实现和标准化。 这个和我们平时开发的时候,一般会将系统功能分解,然后将复杂的问题分解为容易理解的更小的问题是相对应的,这些较小的问题具有更好的边界(目标和接口)定义
各层常见协议有哪些
- 应用层:HTTP、SMTP、FTP、SSH、DNS
- 传输层:TCP、UDP
- 网络层:TCP/IP、ARP、ICMP、NAT
HTTP基于TCP还是UDP
HTTP/3.0 之前是基于 TCP 协议的,而 HTTP/3.0 将弃用 TCP,改用 基于 UDP 的 QUIC 协议 。
TCP三次握手四次挥手
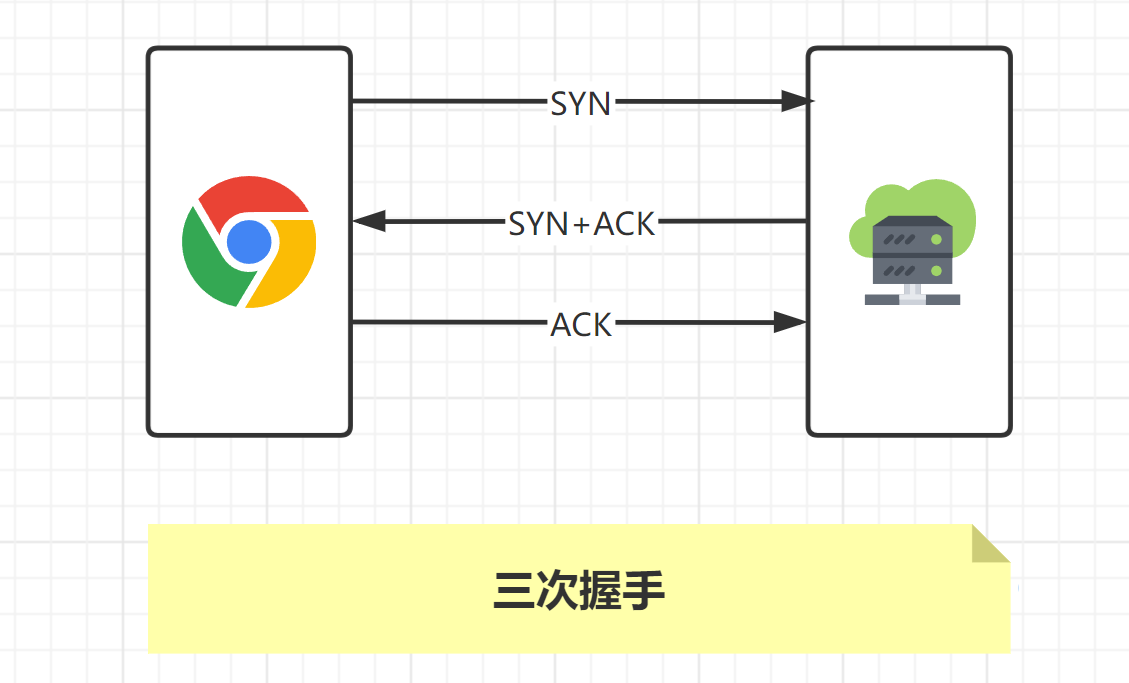
TCP三次握手
三次握手的目的是建立可靠的通信信道,说到通讯,简单来说就是数据的发送与接收,而三次握手最主 要的目的就是双方确认自己与对方的发送与接收是正常的。
- 第一次握手:Client 什么都不能确认;Server 确认了对方发送正常,自己接收正常
- 第二次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:对方发送正常,自己接收正常
- 第三次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己发送、接收正常,对方发送、接收正常
为什么要TCP四次挥手
TCP 是全双工通信,可以双向传输数据。任何一方都可以在数据传送结束后发出连接释放的通知,待对方确认后进入半关闭状态。当另一方也没有数据再发送的时候,则发出连接释放通知,对方确认后就完全关闭了 TCP 连接。
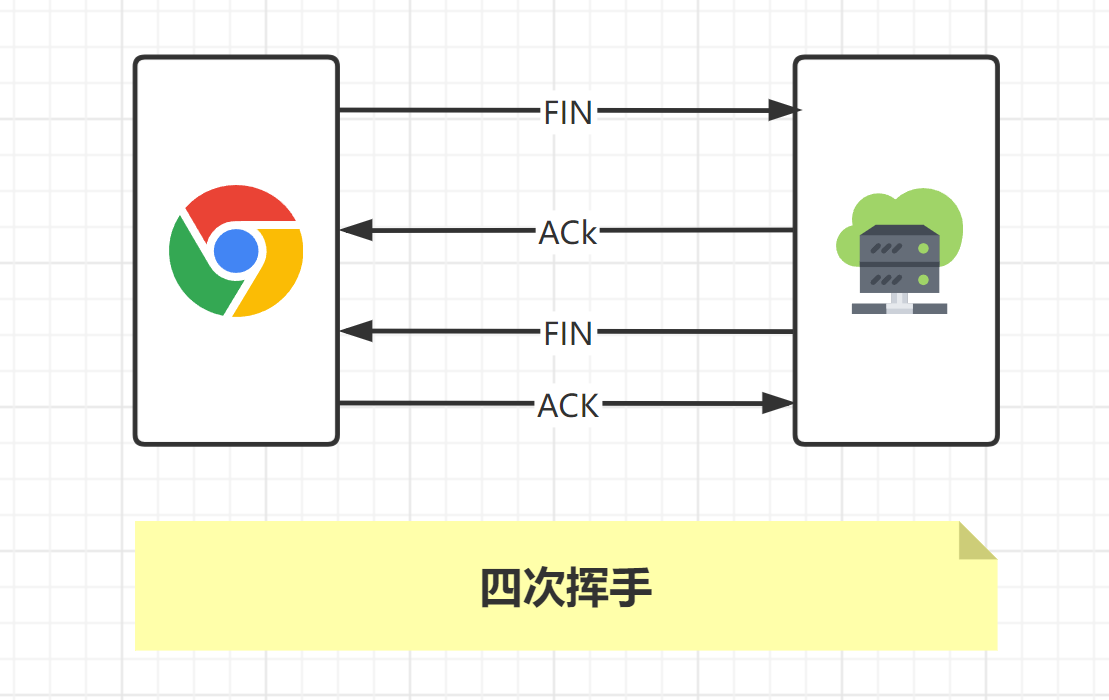
为什么不能把服务器发送的 ACK 和 FIN 合并起来,变成三次挥手?
因为服务器收到客户端断开连接的请求时,可能还有一些数据没有发完,这时先回复 ACK,表示接收到了断开连接的请求。等到数据发完之后再发 FIN,断开服务器到客户端的数据传送。
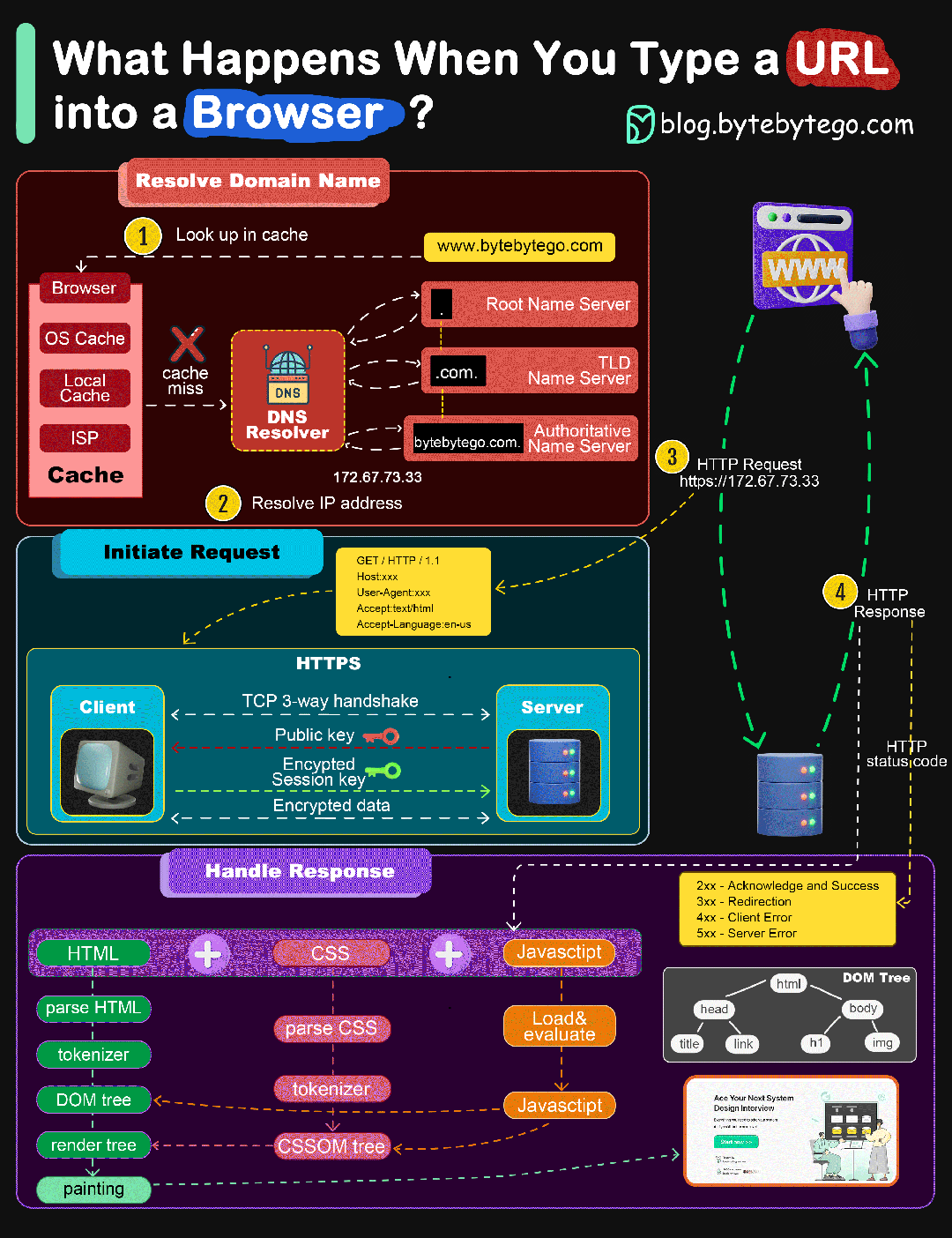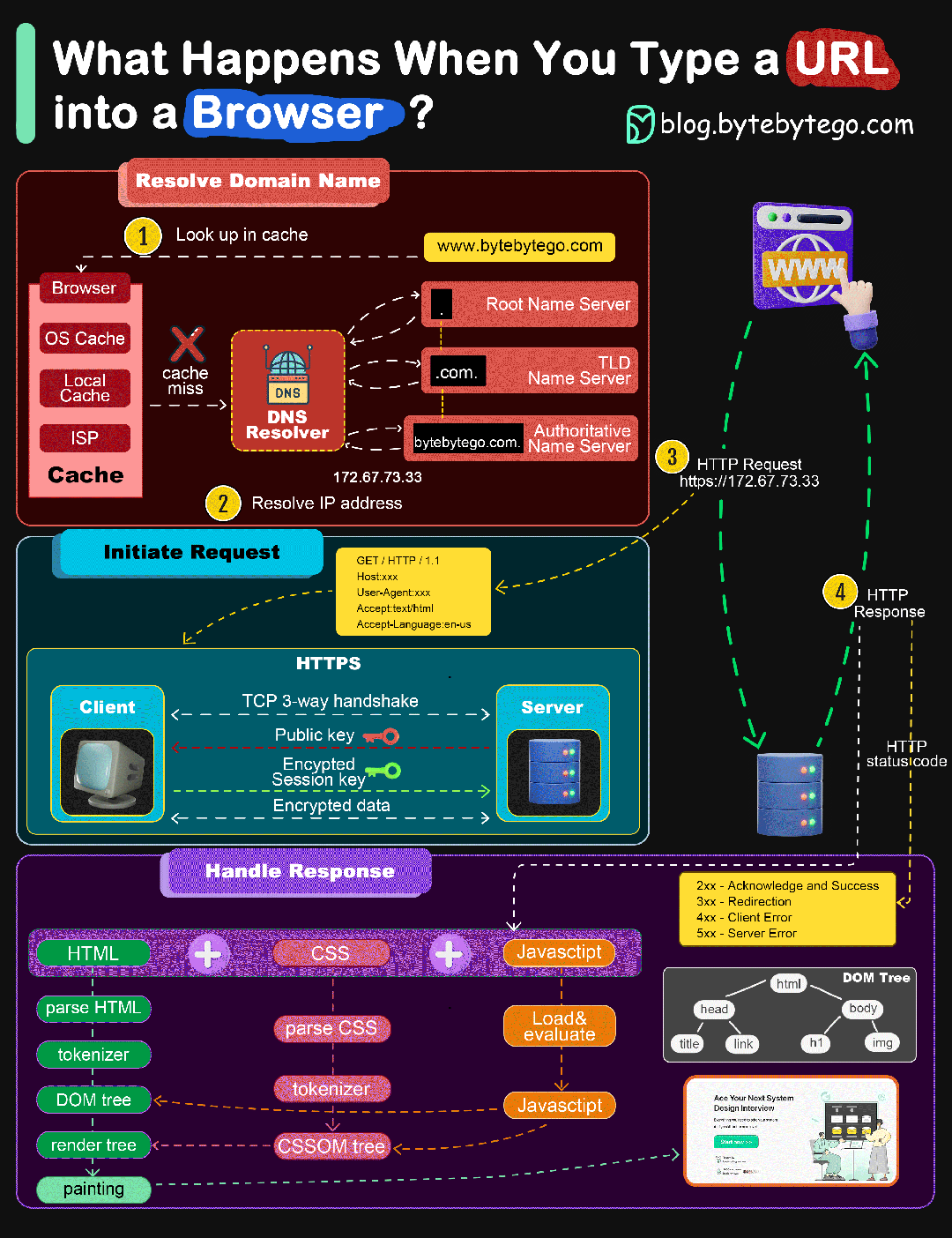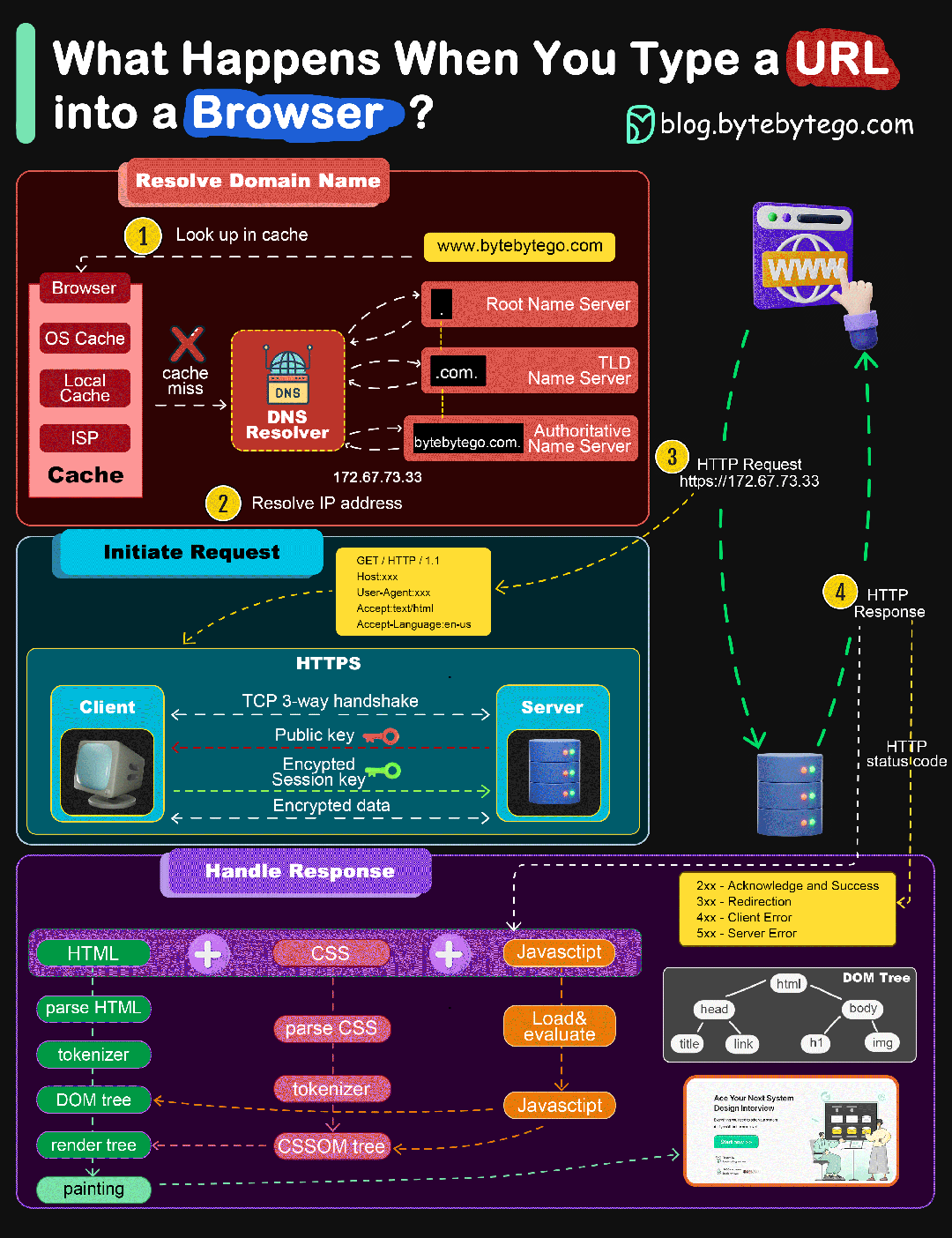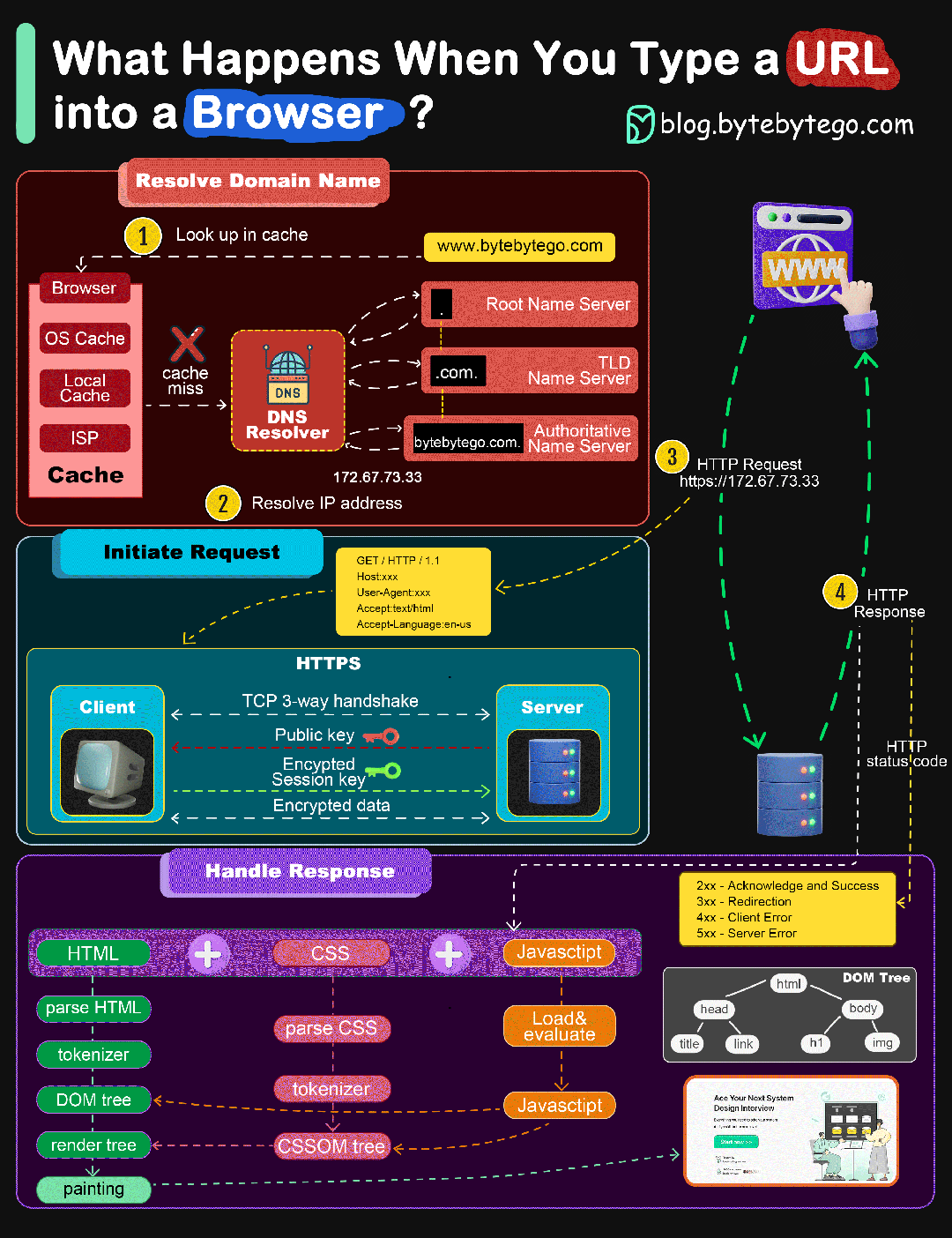
当我们从浏览器输入URL并按下回车的过程发生了什么
- 在浏览器中输入指定网页的 URL
- 浏览器查找域名对应IP地址:浏览器缓存 ==> 主机HOST ==> 路由器缓存 ==> DNS缓存 ==> 根域名解析服 务器
- 建立TCP请求,然后发送HTTP请求
- 服务器收到HTTP请求之后进行处理,并返回HTTP响应数据给浏览器
- 浏览器根据JS代码、HTML渲染网页
HTTP/1.0和HTTP/1.1有什么区别
连接方式 : HTTP/1.0 为短连接,HTTP/1.1 支持长连接。HTTP 协议的长连接和短连接,实质上是 TCP 协议的长连接和短连接。
状态响应码 : HTTP/1.1 中新加入了大量的状态码,光是错误响应状态码就新增了 24 种。比如说,100 (Continue)——在请求大资源前的预热请求,206 (Partial Content)——范围请求的标识码,409 (Conflict)——请求与当前资源的规定冲突,410 (Gone)——资源已被永久转移,而且没有任何已知的转发地址。
缓存机制 : 在 HTTP/1.0 中主要使用 Header 里的 If-Modified-Since,Expires 来做为缓存判断的标准,HTTP/1.1 则引入了更多的缓存控制策略例如 Entity tag,If-Unmodified-Since, If-Match, If-None-Match 等更多可供选择的缓存头来控制缓存策略。
带宽:HTTP/1.0 中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP/1.1 则在请求头引入了 range 头域,它允许只请求资源的某个部分,即返回码是 206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
Host 头(Host Header)处理 :HTTP/1.1 引入了 Host 头字段,允许在同一 IP 地址上托管多个域名,从而支持虚拟主机的功能。而 HTTP/1.0 没有 Host 头字段,无法实现虚拟主机。
HTTP/1.1 和 HTTP/2.0 有什么区别?
多路复用(Multiplexing):HTTP/2.0 在同一连接上可以同时传输多个请求和响应(可以看作是 HTTP/1.1 中长链接的升级版本),互不干扰。HTTP/1.1 则使用串行方式,每个请求和响应都需要独立的连接,而浏览器为了控制资源会有 6-8 个 TCP 连接都限制。这使得 HTTP/2.0 在处理多个请求时更加高效,减少了网络延迟和提高了性能。
二进制帧(Binary Frames):HTTP/2.0 使用二进制帧进行数据传输,而 HTTP/1.1 则使用文本格式的报文。二进制帧更加紧凑和高效,减少了传输的数据量和带宽消耗。
头部压缩(Header Compression):HTTP/1.1 支持Body压缩,Header不支持压缩。HTTP/2.0 支持对Header压缩,使用了专门为Header压缩而设计的 HPACK 算法,减少了网络开销。
服务器推送(Server Push):HTTP/2.0 支持服务器推送,可以在客户端请求一个资源时,将其他相关资源一并推送给客户端,从而减少了客户端的请求次数和延迟。而 HTTP/1.1 需要客户端自己发送请求来获取相关资源。
HTTP/2.0 和 HTTP/3.0 有什么区别?
传输协议:HTTP/2.0 是基于 TCP 协议实现的,HTTP/3.0 新增了 QUIC(Quick UDP Internet Connections) 协议来实现可靠的传输,提供与 TLS/SSL 相当的安全性,具有较低的连接和传输延迟。你可以将 QUIC 看作是 UDP 的升级版本,在其基础上新增了很多功能比如加密、重传等等。HTTP/3.0 之前名为 HTTP-over-QUIC,从这个名字中我们也可以发现,HTTP/3 最大的改造就是使用了 QUIC。
连接建立:HTTP/2.0 需要经过经典的 TCP 三次握手过程(由于安全的 HTTPS 连接建立还需要 TLS 握手,共需要大约 3 个 RTT)。由于 QUIC 协议的特性(TLS 1.3,TLS 1.3 除了支持 1 个 RTT 的握手,还支持 0 个 RTT 的握手)连接建立仅需 0-RTT 或者 1-RTT。这意味着 QUIC 在最佳情况下不需要任何的额外往返时间就可以建立新连接。
队头阻塞:HTTP/2.0 多请求复用一个 TCP 连接,一旦发生丢包,就会阻塞住所有的 HTTP 请求。由于 QUIC 协议的特性,HTTP/3.0 在一定程度上解决了队头阻塞(Head-of-Line blocking, 简写:HOL blocking)问题,一个连接建立多个不同的数据流,这些数据流之间独立互不影响,某个数据流发生丢包了,其数据流不受影响(本质上是多路复用+轮询)。
错误恢复:HTTP/3.0 具有更好的错误恢复机制,当出现丢包、延迟等网络问题时,可以更快地进行恢复和重传。而 HTTP/2.0 则需要依赖于 TCP 的错误恢复机制。
安全性:HTTP/2.0 和 HTTP/3.0 在安全性上都有较高的要求,支持加密通信,但在实现上有所不同。HTTP/2.0 使用 TLS 协议进行加密,而 HTTP/3.0 基于 QUIC 协议,包含了内置的加密和身份验证机制,可以提供更强的安全性。
SSE 与 WebSocket 有什么区别?
SSE 是基于 HTTP 协议的,它们不需要特殊的协议或服务器实现即可工作;WebSocket 需单独服务器来处理协议。
SSE 单向通信,只能由服务端向客户端单向通信;WebSocket 全双工通信,即通信的双方可以同时发送和接受信息。
SSE 实现简单开发成本低,无需引入其他组件;WebSocket 传输数据需做二次解析,开发门槛高一些。
SSE 默认支持断线重连;WebSocket 则需要自己实现。
SSE 只能传送文本消息,二进制数据需要经过编码后传送;WebSocket 默认支持传送二进制数据。

